
Greetings, readers, here’s a riddle for you to solve: Figure 1 presents part of a Spanish family tree, showing how Spanish naming conventions work. If you don’t already know this, take a look at it, and see if you can figure out the family names for Marta and Carlos at the bottom of the chart.
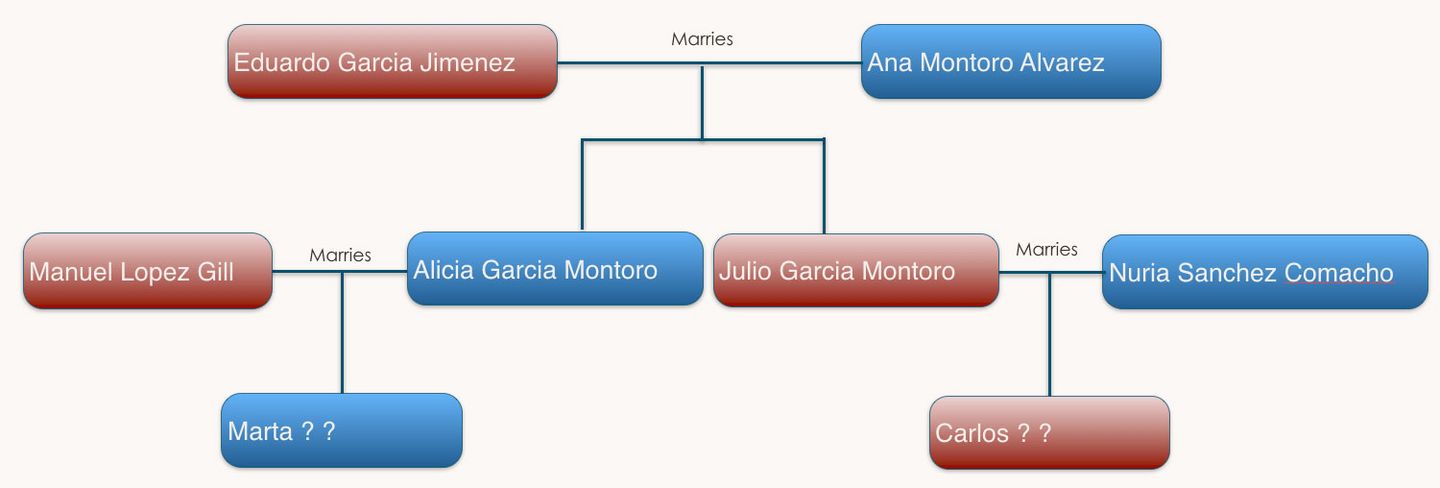
Figure 1: Diagram showing Spanish naming conventions. What will the family names be for Marta and Carlos?
Source: Ray Gallon, The Transformation Society
In all probability, you had no problem deducing the answer[1], even if you knew nothing about the subject beforehand. The chart provides enough of an example that most people are able to generalize from the examples to a new case.
This capacity to generalize is key to many learning situations. It is pivotal to designing user assistance. Roger C. Schank, researcher in Artificial Intelligence (AI) and machine learning, and a specialist in ...