AI is one of the biggest buzzwords in general technology, and in IT in particular. So, what impact does it have on the technical communication ecosystem – today and in the near future?
What is (linguistic) AI?
Let’s start with a proper definition of AI. Colloquially, the term "Artificial Intelligence" is often used to describe machines (or computers) that mimic "cognitive" functions that humans associate with the human mind, such as "learning" and "problem solving".
As this is a wide field, divided into multiple subcategories, in this article I will focus on the subcategory with the most obvious impact on technical communication: linguistic AI. This combines three subjects: language processing, language understanding and language generation – powered by machine learning (ML).
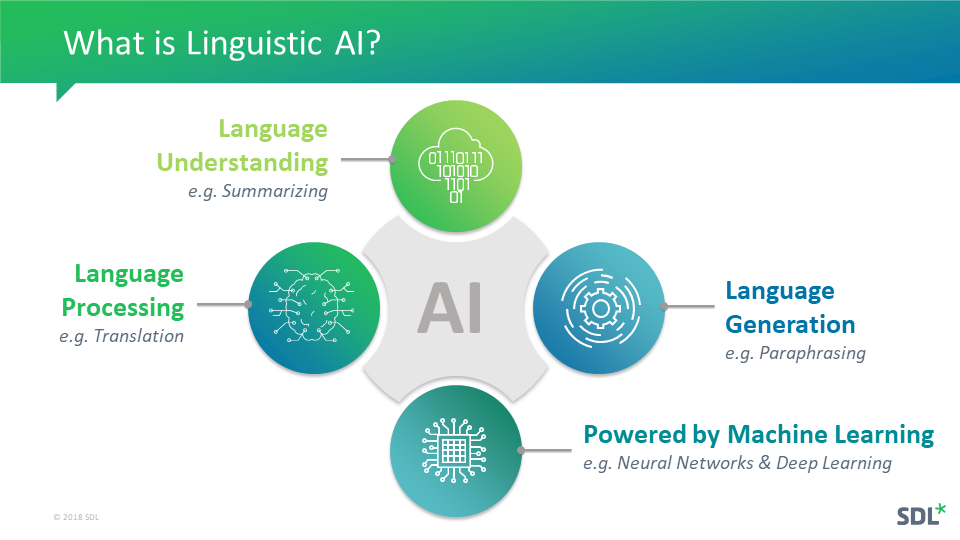
Figure 1: What is linguistic AI?
As in all neural technology using machine learning, successful implementation of linguistic AI applications is based on three main pillars:
- Machine learning competence
Deep expertise in ML techniques and algorithms is a core requirement - Good data
AI ...
Read more after login
tekom members can log in directly with their "My tekom" access data.
You are not yet a tekom member, but would like to read one or more articles in full? Then you have the opportunity to register on the internet portal of the technical journal 'tcworld' without obligation. Once you have registered, you can select any three specialist articles and view them in full for a period of two months. The selection will then be deleted and you can select three new articles for the next two months.
As a tekom member you benefit from the following advantages::
- Online access to all articles of the trade magazine 'tcworld magazine'
- Exclusive specialist articles from all areas of technical communication
- Regular new articles from over 300 authors
- The technical journal 'tcworld magazine' as a printed edition
- Reduced admission prices to tekom conferences
- Membership fees for tekom publications
- Access to 'my tekom', the web forum with job offers / job requests, appointments, expert advice, service provider file and much more
Login
Registration
Promised: The trade magazine 'tcworld magazine' is the best we have. And we don't make the choice easy for ourselves. Every month, the editorial staff of the technical journal 'tcworld magazine' publishes the latest articles by renowned authors. This demanding selection is available exclusively to members of tekom (as usual, including the printed edition).
The trade magazine 'tcworld magazine' stands for intelligently prepared specialist articles, texts written to the point, informative content, surprising insights, international perspectives and communicates technical communication in an understandable, fast, clear and uncomplicated way - exclusively for you.
