
Close your eyes for a moment and think of a content repository, any repository. It could be one of your client repositories or your own internal document store. What do you picture? Many of us might think of a landfill: a plethora of spreadsheets, Word files, PowerPoint decks, and images, not particularly well-organized or well-named. Folders are peppered with filenames such as “architectural framework v3 final” or “new proposal – longer description” or “client report_final_final_final”.
But here’s the thing: Even landfill sites are organized into a grid system - this nugget of information comes from true crime shows – where a forensic search can unearth deposits from a particular source or date. Whether it’s a landfill site or a repository, findability relies on some sort of structure.
How AI uses content structure
Structuring content helps AI understand, generate, and retrieve information more effectively. Structure enables efficient automation, delivering personalized content, and more accurate responses.
By producing content in modular, machine-readable formats, using clear on-page structures such as headings, and metadata such as semantic HTML, AI can interpret and more reliably process content.
Eight structural techniques
Content can be structured at multiple levels, and each level of structure brings its own advantages. The benefits are not hierarchical, with some structures being more beneficial than others. In reality, the structures work in tandem to bring exponential benefits.
You can consider the distinction between structure types as on-page structures and off-page structures, or a document-specific treatment vs a body-of-knowledge treatment. Below, we will summarize each type of structure, starting with editorial (on-page) conventions, followed by lexical and architectural (off-page) structures.
Editorial aspects
The first two structures discussed involve how content is viewed on a page.
Editorial conventions
What is often called “editorial structure” is actually a set of editorial conventions. Those conventions can change from culture to culture, but in English-based content, the conventions are relatively codified. In Figure 1, you can tell what the elements are, simply by looking at their placement and sizes.

Figure 1: Editorial conventions
You can identify images, headings, subheadings, footers, page numbers, bullet points – all because there is a common understanding about how the conventions work. If someone were to, for example, leave out the paragraph preceding a bulleted list, nothing prevents you from saving the document. The omission just means that the consumers of the content have to work a bit harder to understand the significance of the bullet points. Marketing material and advertisements break these conventions all the time, and we still understand the message.
Editorial structure
Editorial structure has both editorial and technical implications. Let’s take a look at a recipe, which is a great example because it contains many elements. Underneath the content are multiple structural elements, specifically tag pairs, that machines “read” to process the content between the tags. The way that those tags get processed makes it easier for people to understand the editorial elements of the recipe.
Each ingredient is tagged with a specific structural tag that clearly classifies it as an ingredient. This distinguishes the way that ingredients are displayed compared to, say, steps in the instructions. For example, if the wrong structural tags were applied, you might confuse the preparation time with the number of servings.
An additional benefit of tags is that when recipes get syndicated and shared across sites, the structure and content-level semantics support this automation. To take the example further, one could add a tag to a muffin recipe for the ingredient “walnuts”, which allows for the automated elimination of this ingredient and the associated step of adding walnuts to the recipe, if you were sending this recipe to a nut-free recipe site.
As you can see, editorial structures are more rigid than editorial conventions, to enable machine-readability and ultimately consumer comprehension.
Lexical aspects
How we name things is important, and metadata is central to adding labels to help machines understand not only the content but also the context. The starting point then is to get a handle on our vocabulary – not necessarily to restrict it, but to harness it for information enablement purposes.
Taxonomy
A taxonomy is a hierarchical categorization of concepts within a domain. For example, a simple taxonomy of some plant types would look something like Figure 2.
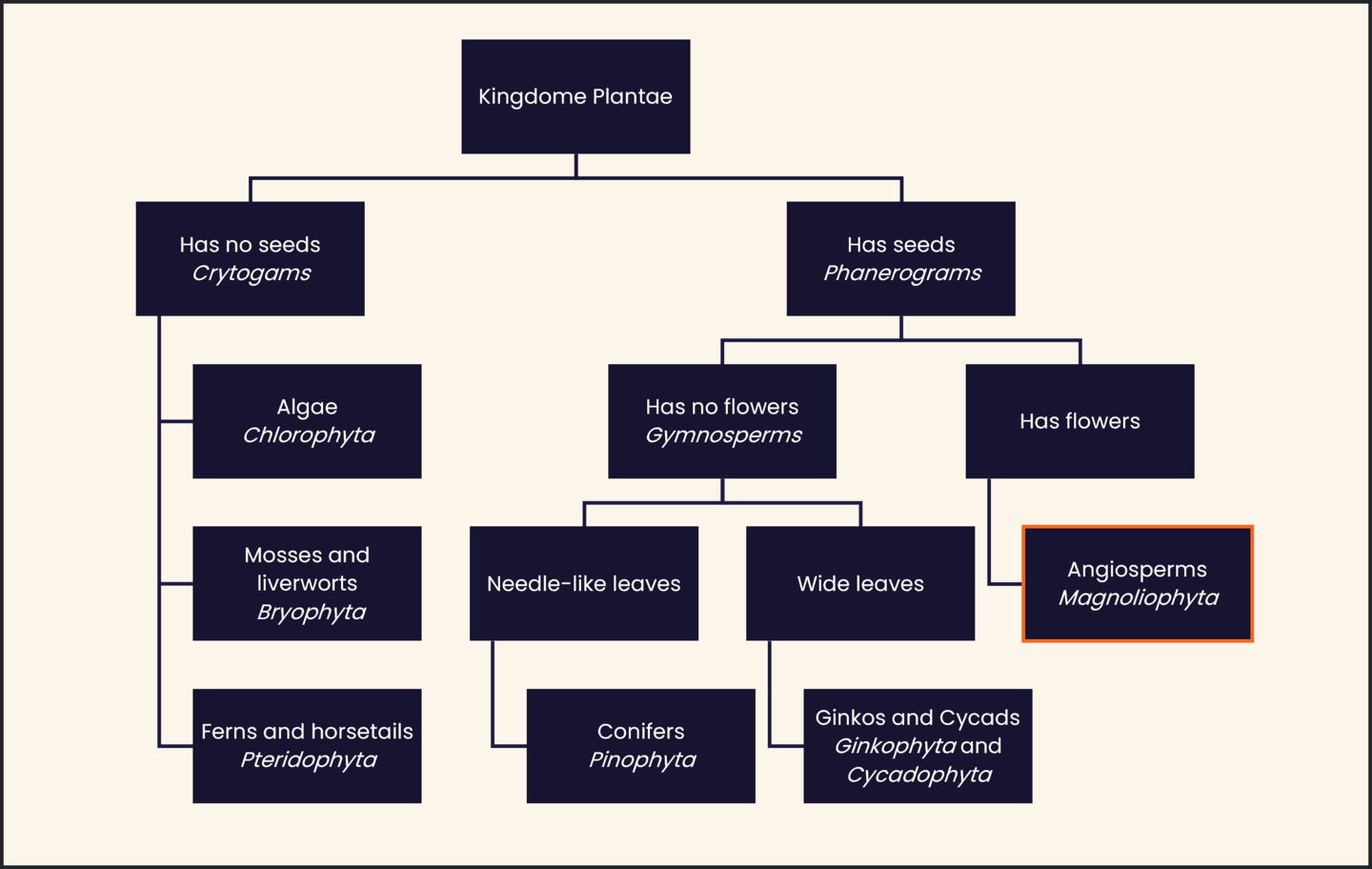
Figure 2: Sample taxonomy
Thesaurus
A thesaurus is a taxonomy enriched with metadata. This enrichment is achieved by adding equivalency terms. In a hierarchy of parent-child relationships, these terms would be sibling terms. They are often synonyms, though not always. Going back to our taxonomy of plants, in the clade of Angiosperms is a subcategory, the family of Solanales. This is better known as the nightshade or potato family. Within that is the Atropa genus, which includes Solanum tuberosum (potato), Solanum lycopersicum (tomato), Solanum melogena (aubergine), and Capsicum (chili peppers). Tomatoes may be a synonym for the technical term, while various types of tomatoes are equivalents, though strictly not synonyms – the tomatillo, for example, is in the Physalis genus, though they taste similar, and we would find them in the same area of a supermarket.
Lexicon
A lexical database of an organization's vocabulary is needed to synchronize terminology across the enterprise. According to Kara Warbuton, a terminology professor, an organization’s core language should be represented in a robust database before you can build a taxonomy on top of it.
Architectural aspects
Other types of structures involve the organization of content. Some of the ways are structural, while others are relational.
Ontology
An ontology brings a new level of complexity, one that involves creating relationships between multiple taxonomies. Seth Earley, a prominent taxonomist in the USA, says to think of ontologies as “master data management” for AI.
Ontologies identify all the entities in a domain, and use a description technique called RDF triples, which builds relationships that give meaning to data. A concept or data point is expressed with a subject, predicate, and object, which provides a lot of context. Figure 3 shows a simple example.
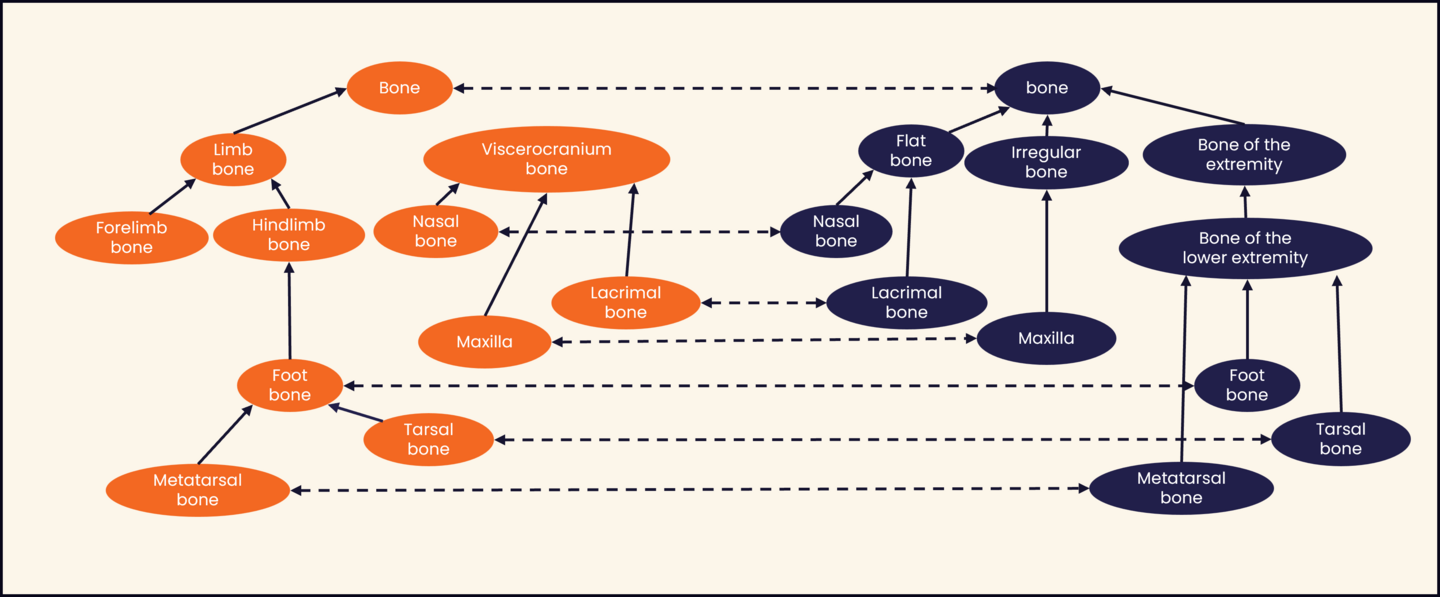
Figure 3: Example of an ontology network with two ontologies (with roots 'bone') and an alignment.
Source: Creative Commons - Scientific Figure on ResearchGate
Knowledge graph
The knowledge graph is an instance of an ontology. Knowledge graphs act as “knowledge scaffolding” that can give a company insights into things like user preferences – think of Netflix knowing that you like documentaries or romcoms, or action movies.
An ontology could be, for example, a classification of music that establishes relationships between the various genres, artists, instruments, and so on. Music labels might use a knowledge graph to establish relationships that are not defined in the ontology, such as which artist is assigned to which agent, which countries their music is licensed to play in, and so on.
Information architecture
Information architectures are often confused with taxonomies. A simple example to explain the difference is how tableware is laid out in a kitchen and a dining room. A taxonomy is the system you use to store flatware, glasses, and cutlery, whereas an information architecture is how we assemble those elements to make sense to users: the place settings presented with one plate, one glass, and one set of cutlery per person.
Using the example of how Netflix knows that you like documentaries or Bollywood movies, how can Netflix recommend other documentaries or Bollywood movies to you unless they have categories called Bollywood or Documentaries?
This is where information architecture comes in. A bookstore can group books of the same genre (murder mysteries), or topic of interest (Roman Empire), or even in the right language (French) because they have categories for each of those topics. Information architecture plays an important foundational role for AI to deliver better results, be it better options or better answers to a specific query.
Practical application of structure
So far, we’ve looked at the eight different types of structure that can be applied to content. Each one has a function of its own, but the power of these functions increases exponentially when they’re combined. Let’s look at an example of how this could be applied.
A common business objective is to make customer support self-serve. All of a company’s customer-facing information gets put into a portal and attached to an AI-enabled chatbot for natural language queries, so customers can get an answer – the right answer. However, an issue that continues to plague AI is inaccuracies or ambiguities, and specifically hallucinations. To reduce hallucinations, we can add various types of guardrails.
One of those structural guardrails is information architecture. Information architecture controls where the AI is allowed to draw answers from, where it’s not allowed to look, and what the response should be if no answer is found.
Another type of guardrail is semantics. Semantics has become a very broad class that includes everything from metadata from knowledge graphs and ontologies, right down to tagging and vocabulary. Semantic guardrails are related to “Retrieval Augmented Generation” or RAG.
RAG models are powerful guardrails to reduce hallucinations and increase the accuracy of answers generated in response to natural language queries. A RAG model uses multiple techniques to ensure that the answers sought from a knowledge base or other repository are correct.
- Retrieval: The AI looks into a specified repository to find information.
- Generation: An LLM generates a reply in a natural language format.
- Augmentation: This is a combination of what happens “on page” plus additional context from a knowledge graph, some constraints through information architecture, content structures, and the metadata on this structured content, and other technical things, such as chunking, which is an AI-specific concept that breaks text down into manageable units. Combining those techniques greatly increases the predictive likelihood of getting the single best result for any given query.
Connecting structure to business value
Companies want to use AI to unlock some sort of value. This could be value to customers or the value of operational efficiency. In many environments, so much content is generated that over 25% of daily staff time is spent looking for information - not just any information but the right version of the right document for the right purpose. That is a lot of wasted time – more than a day every week.
From a customer point of view, value is not measured in terms of time spent retrieving information or customer support calls when self-serve fails. However, we do measure the cost of customer acquisition, which is a staggering five to seven times the cost of customer retention. That creates a huge incentive to ensure that customers can be served in the most efficient and effective ways, whether that is a direct self-serve model or quickly getting the right information to customer support agents whose performance is measured by instance resolution.
When Altuent is helping corporations get their customer content ready for consumption by AI, we not only look at accuracy; we examine an entire range of factors that preserve the integrity of content to get better answers from AI queries.
Content structure alone will not ensure that an LLM can serve up accurate information, but structure does contribute heavily to a successful outcome.