
AI craves your words
Will AI steal the jobs of technical communicators?
I answer this question with a definitive "no". As advanced AI permeates society, the value of high-quality content – i.e., the source information crafted through hands-on observation and a deep understanding of the actual machines – is increasing more than ever.
AI lacks a physical body. Therefore, investigating actual machines, pressing switches, and verifying machine behavior is a process only humans can perform. This step, which elevates the chaotic reality of physical entities into logical information, is the source of value that AI craves most but can never access on its own. Every line we craft is a reality anchor enabling AI to interpret reality correctly and guide users safely.
The shift to Answer Engine Optimization
We are transitioning from an era where humans enter keywords into search boxes to an era of Answer Engine Optimization (AEO), where AI agents autonomously acquire information and generate answers. This is the point in time where manufacturers must reclaim information governance. We must stop letting AI guess based on probabilistic reasoning and instead control AI using the facts we have defined.
No need to burn the secret recipe
Do we have to completely change our traditional creation methods and start writing highly fragmented information just for AI? The bottom line is: You do not need to change your conventional production style. Each company possesses formats cultivated over many years, and you do not need to forcefully dismantle them. By applying a common meaning behind the scenes – specifically with the help of the international standard iiRDS and its specification for smart manufacturing IEC PAS 63485 – you can leverage AI to automatically convert your content into "AI-ready" data.
Quality in, certainty out
In the AI era, we invert "garbage in, garbage out" into a positive concept: "quality in, certainty out": High-quality source information yields a certain answer experience. Understanding the actual machine and converting this understanding into words serves as the premium fuel that drives the AI engine. What I present in this article is the construction process of a new information blueprint for the AI era, moving from V1 (Construction) to V2 (Dilemma), and finally reaching V3 (AEO Architecture).
|
The limits of PDF-based RAG
With the rise of generative AI, many expect that simply throwing manual PDFs into RAG (Retrieval-Augmented Generation) systems allows AI to read and answer flawlessly. However, a massive pitfall lies here.
On the shop floor, the greatest weakness of AI is not its ignorance, but its goodwill. If AI cannot find the correct answer, it avoids giving an unhelpful "I couldn't find it" response. Instead, it synthesizes general information from the internet or from incorrect contexts. This actively sows the seeds for accidents.
Experiment 1: Semantic contamination
To visualize this risk, we fed a RAG system a manual for the fictional "Smart Pump SP-X Series" (see Appendix A). The standard SP-X100 uses a heater (burn risk), while the overseas SP-X200 uses a solvent (chemical burn risk).
When asked about the SP-X200's risks, the AI erroneously listed the "heater burns" specific to the SP-X100. The AI suffered from semantic contamination. Because the unstructured source text did not explicitly state the subject for each risk, the AI probabilistically combined information related to "burns".
Experiment 2: AI cannot pinpoint locations
An even more severe risk involves physical positional relationships. We asked the RAG system to determine the physical location of the "UP key". Since the original PDF only depicted the location in a diagram and omitted it from the text, the AI referenced general internet knowledge and fabricated a plausible lie: "The UP key is in the middle of the left side."
If a user executes an emergency stop based on this fabrication, it invites disaster. This scenario exposes the danger of lacking a "design of silence" – guardrails forcing the AI to remain silent when information is missing. We must organize this digital landfill and secure "search hygiene" so that AI can reach the correct answer via deterministic retrieval rather than probabilistic guesses.
Step 1: Generation – Transforming physical reality into "information assets"
Designing the Generation AI
The first step on the road to trustworthy AI is the "Generation" phase, applying logical molds to fragmented text. We utilized the international standard iiRDS not merely as a glossary, but as structural constraints that strictly dictate the AI's thought processes.
We integrated a subset of iiRDS guidelines into the prompt as guardrails to lock the AI's reasoning (see Appendix B). We established three governance policies:
- Semantic segmentation: Slicing information where the content's nature changes
- Complete separation of model variants: Physically separating SP-X100 and SP-X200 information to eradicate RAG confusion
- Self-contained context: Each chunk must possess independent metadata
Execution and semantic chains
The system successfully generated eleven structured chunks from the plain text (see Appendix C). By applying the iiRDS vocabulary, the AI accurately extracted the Semantic Chain / SPO (Subject, Predicate, Object) from the text:
- Subject: Chemical-Resistant Model (SP-X200)
- Predicate: Tools used
- Object: Ceramic wrench
With these semantic links fully determined, the AI can answer based on deterministic facts, completely eliminating probabilistic guesswork.
Step 2: Audit – Dual governance enforcing norms on AI
But where is the guarantee that the AI-generated structure is correct? We advocate dual governance, i.e., establishing a separate AI reviewer agent to act as a "senior knowledge auditor".
The four quality standards
This Auditor AI verifies quality based on four criteria (see Appendix D):
- Information completeness (loss check): Are safety warnings retained verbatim?
- Attribute consistency (variant check): Is the model separation accurate?
- Metadata validity (metadata check): Is the tagging optimal according to iiRDS?
- Chunking appropriateness (granularity check): Is the granularity appropriate for RAG?
The blind spots exposed and "intentional subtraction"
During execution, the Auditor AI issued a critical "NG”. The Generation AI had perfectly handled model separation but completely omitted the fundamental DocumentType metadata. Holding iiRDS as an absolute yardstick, the Auditor AI accurately pinpointed this blind spot.
However, there is no single, absolutely correct solution here. The Auditor AI recommended tagging specific numbers in the maintenance overview as technical data. I deliberately rejected this. Attaching specification tags to lengthy overview information causes it to hit as noise during specific searches, degrading RAG accuracy. Resolving this contradiction requires the strategy of "intentional subtraction": AI presents logical options; human knowledge architects choose the strategy.
Step 3: Acceleration – Breaking through the "normalization paradox"
The audited "iiRDS Master Data V1.1" (see Appendix E) is a flawless deliverable for asset management. However, when fed into an actual RAG engine, we faced a desperate paradox.
If we advanced subdivision to improve metadata accuracy, the context became too fragmented. If we consolidated information, attributes of different models mixed. The further we pursued the database ideal (perfect normalization), the deeper the AI's answering accuracy sank. "Atomization" represents the aesthetic of a database, but in the world of RAG, it strips away the sharpness of information. We had to temporarily set aside management structures and redefine information based on how AI answers, leading to V3: the AEO architecture.
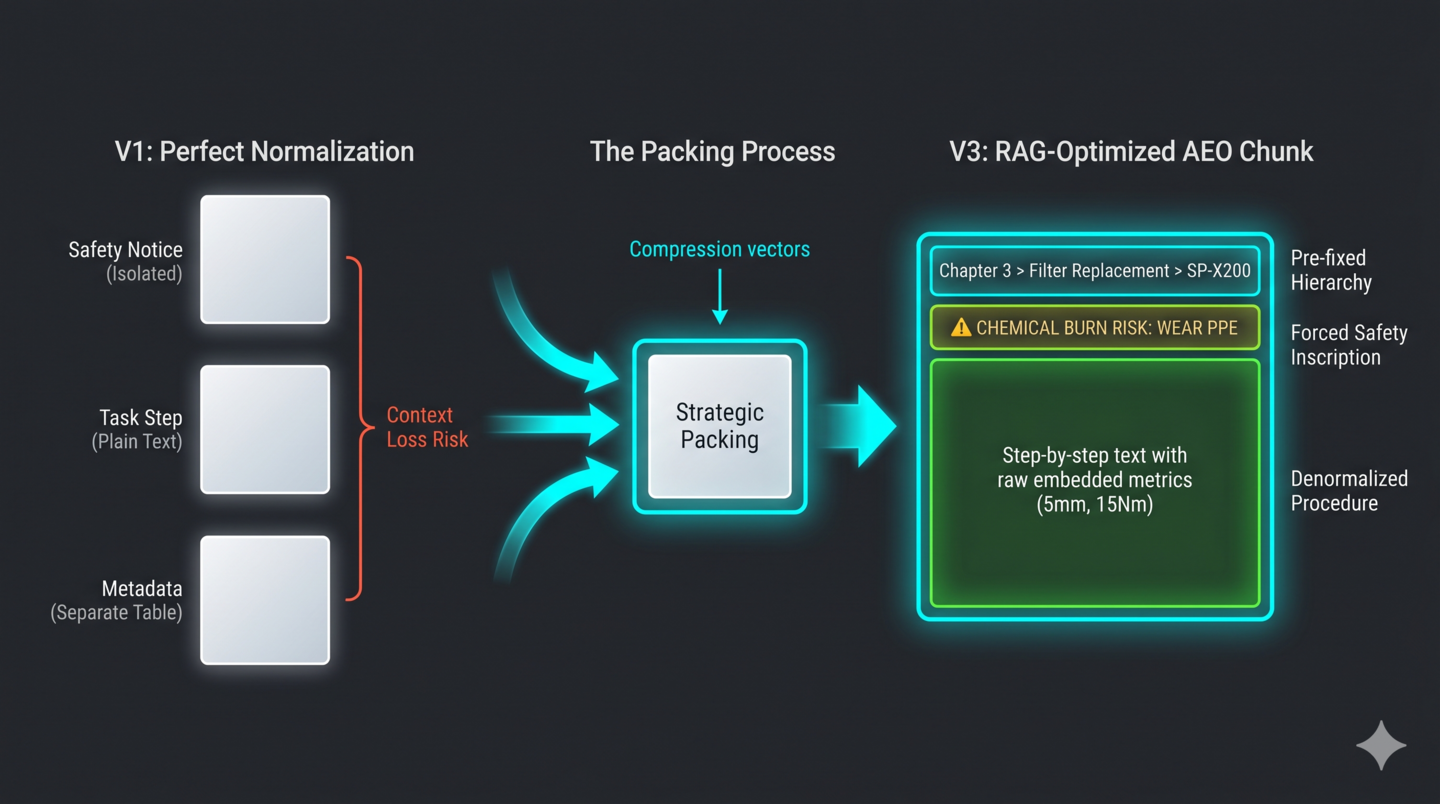
Designing the V3 architecture: Strategic packing
AEO tunes information so that the AI can chess-move to deterministic answers via the shortest route. We inscribed three strategic intentions into the optimization prompt (see Appendix F):
- Forced integration of safety context (point of use): We physically combined independent safety warnings at the very beginning of the procedure. This ensures safety context always attaches when the AI retrieves the procedure, structurally preventing fatal hallucinations.
- Strategic denormalization: We deliberately withheld tags from numerical values within the procedure text, limiting them only to the specification table. This prevents the lengthy procedure manual from hitting as noise, bringing overwhelming sharpness to the answers.
- Prefixing hierarchical information (context protection): We forcefully appended a breadcrumb trail (e.g., Chapter 3 > ...) to all headings. We hardcoded their location directly into the information to eliminate cross-model confusion.
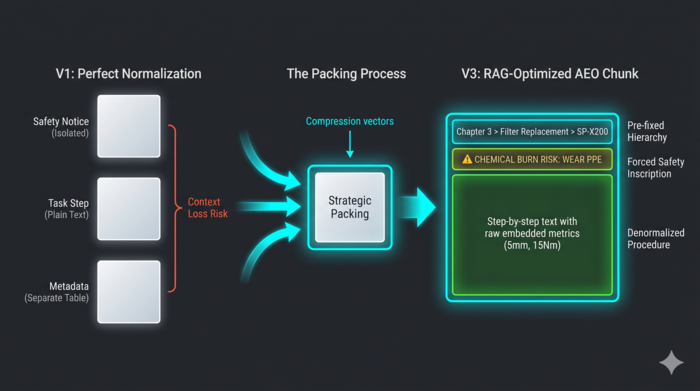
Figure 1: The anatomy of strategic packing – breaking the normalization paradox for RAG optimization
AI governance: A physical interlock
The true value of the V3 architecture lies in enforcing "silence" upon the AI. The metadata attached to the V3 data functions as a physical sensor. By embedding constraints into the runtime prompt, we complete a physical interlock:
"Verify the metadata of the retrieved information. If the requested ProductVariant tag does not exist, strictly prohibit completion via inference, and output 'Cannot answer due to insufficient information.'"
Because the data side holds solid evidence, the runtime prompt can restrict the AI's free inference based on objective facts. This data-driven governance is the true reason we call iiRDS the "reality anchor". Through this strategic packing, the manual was reborn into a highly optimized format of nine refined chunks (see Appendix G), obtaining a perfect verification certificate from our final audit (see Appendix H and Appendix I).
Information architecture in the AI era
In the AEO era, technical documentation transforms into entities that are inevitably selected by AI. If SEO prepares the entrance (search), AEO guarantees the quality of the exit (answer). Structuring information and tuning it for AI generates the DAS framework:
- Discovery: AI can instantaneously pinpoint specific components from massive data.
- Accuracy: Minimizing the risk of semantic contamination by clarifying boundaries
- Sustainability: Reducing unnecessary computation and suppressing power consumption
Feeding unstructured data directly into AI causes the Graphics Processing Unit (GPU) to idle, consuming massive amounts of electricity. Structured data enables AI to search via the shortest route. Physically reducing the computational load directly translates to a reduction in data center power consumption, contributing directly to "green AI".
Information architecture is no longer just about saving the user’s time; it is a sustainable environmental activity. Technical communicators have evolved into professionals of advanced "information tuning", transforming the asset value of information into a trusted answering experience. By touching the actual machine, understanding it, and explaining it in words, we construct the ultimate reality anchor for the AI era.
--
 Read also
Read also
This is Part 1 of the three-part series "Architecting certainty: A hands-on guide to iiRDS-driven AI governance".
![]() Part 1: The blueprint for certainty in the AI era
Part 1: The blueprint for certainty in the AI era
![]() Part 2: From vectors to graphs – How iiRDS connects information
Part 2: From vectors to graphs – How iiRDS connects information
![]() Part 3: When information architecture transforms into a strategic asset
Part 3: When information architecture transforms into a strategic asset
Want to learn more about the intelligent information Request and Delivery Standard? tcworld magazine has got the insights you need to get started with iiRDS:
- iiRDS for Trusted AI
Can we trust AI to deliver reliable information in industries where accuracy is crucial, even vital? Large Language Models enriched through DITA and iiRDS deliver promising results.
- iiRDS/H: Bridging the gap between compliance and intelligence
Technical documentation must juggle strict compliance requirements and the demand for intelligent, context-aware information delivery. The new standard iiRDS/H unites the rigor of VDI 2770 with the flexibility of iiRDS, paving the way for future-proof digital documentation.
- Why iiRDS is a game-changer for small tech writing teams
Small and medium-sized enterprises are faced with the task of modernizing their information products. The intelligent information Request and Delivery Standard (iiRDS) can play a key role here.
- Ten questions about iiRDS
Two founding members of the iiRDS Consortium explain the importance and potential of iiRDS and its integration at Endress+Hauser. An interview with Thomas Ziesing from Endress+Hauser and iiRDS consultant Ulrike Parson from parson AG.
- Enter the age of digitization with iiRDS
The intelligent information Request and Delivery Standard (iiRDS) enables the compliant exchange and delivery of technical information, irrespective of how content is created and stored.