
“And no one puts new wine into old wineskins; or else the new wine will burst the wineskins and be spilled, and the wineskins will be ruined. But new wine must be put into new wineskins, and both are preserved.” Luke 5:37-39
A quote from the New Testament might be the last thing that you expect to see in a magazine on information management, but – apart from grabbing your attention – this quote is here for a reason.
I have been in the content industry for almost 30 years and have seen a lot of successes and failures in implementing content management and content automation solutions. A common failure story can be told about companies that tried to reach new goals by deploying new technology and applying the old content and content processes they have had for years.
What happened then? You guessed it: The new wine burst the wineskins and spilled while the old wineskins were ruined. Or, to put it in TechComm language: Wrapping old content and old processes into a new technology delivered a subpar experience to both content authors and customers.
How new goals dictate new requirements
Why do new goals require the transformation of old habits? To answer this, let’s take a look at the goals that companies may want to pursue. From my time as a documentation manager, consultant, and a founding CEO of two companies in the industry, I can say that companies implement content management solutions because they want to
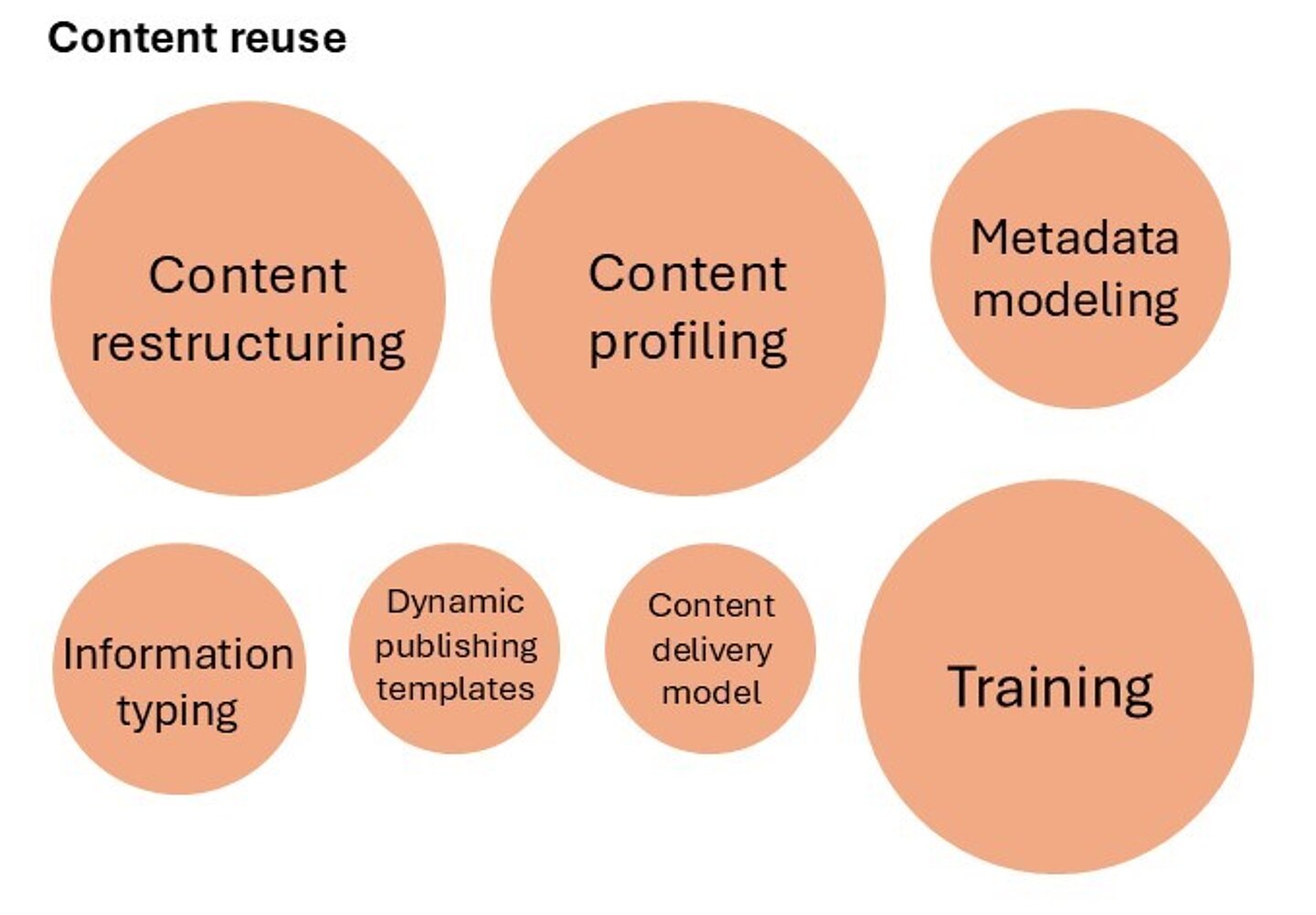
- make their content reusable (preferably on different levels)
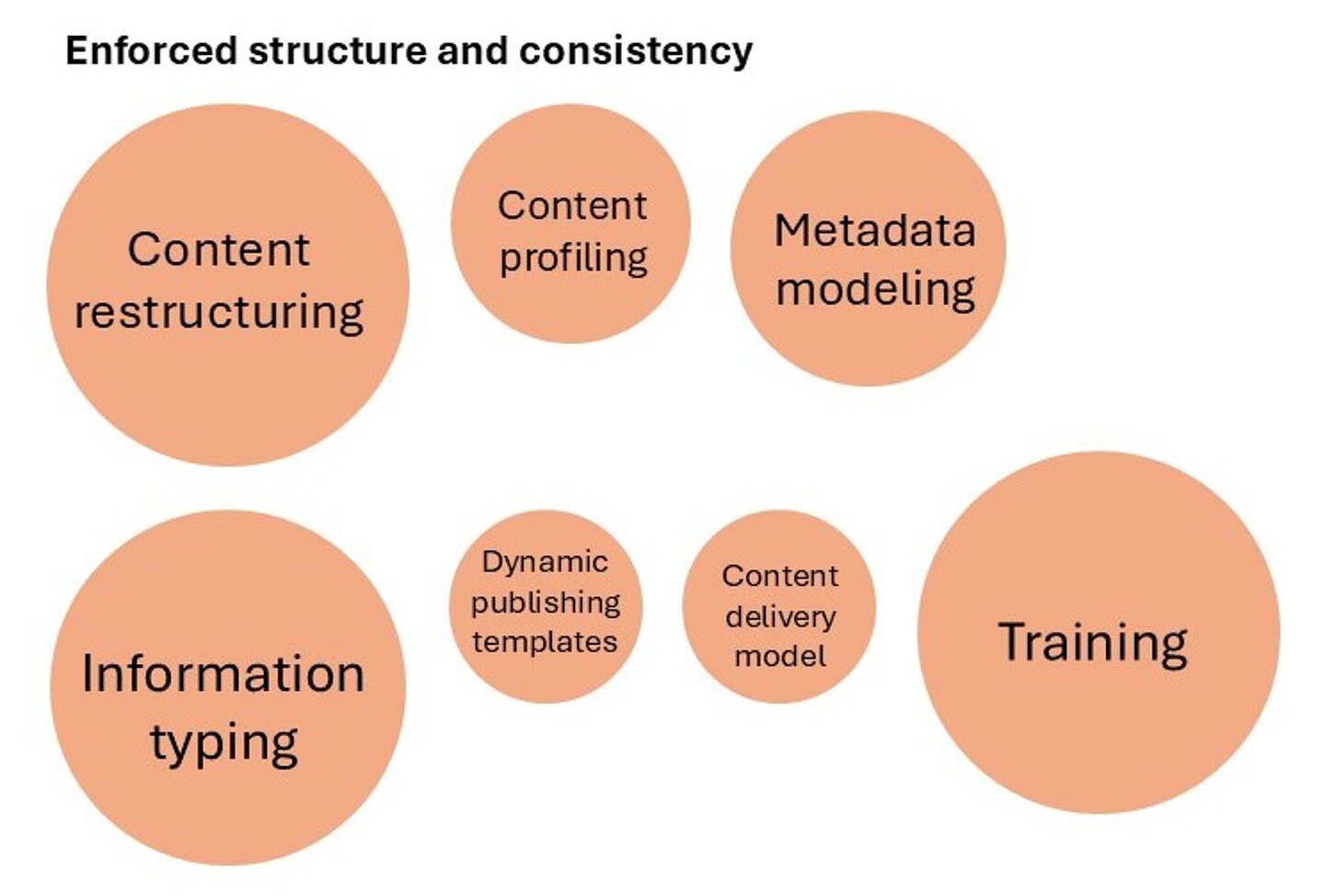
- enforce structure and consistency
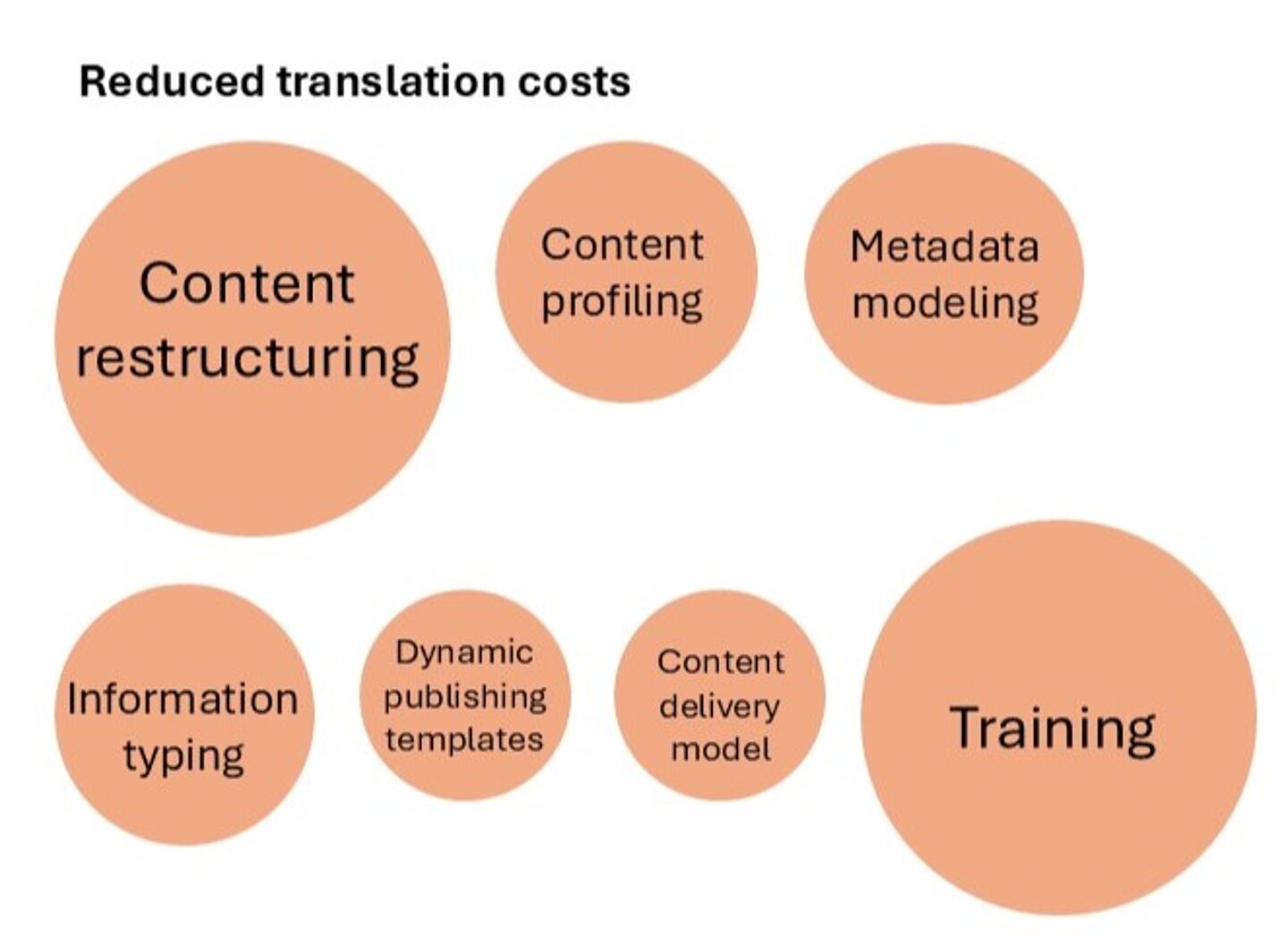
- reduce translation costs
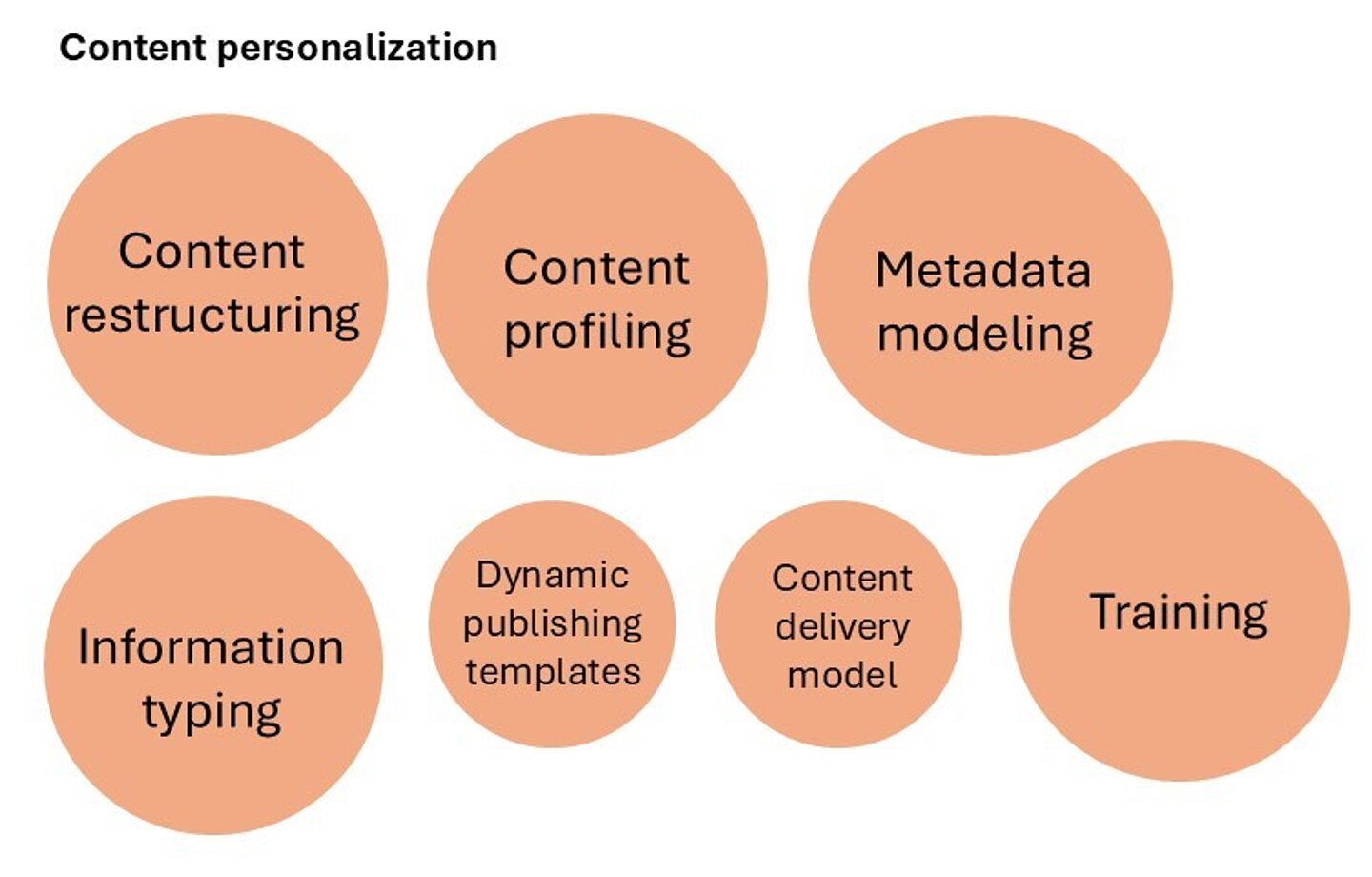
- personalize content by tailoring it to the customer’s context and specific product configurations
- reduce customer service costs through self-service solutions
- speed up content time-to-market and increase content quality by assembling product content automatically based on the product configuration
The company does not have to want to achieve all of them. They may want to start with something modest and simple, like making content reusable. However, all of these goals have one thing in common: They all imply that the content meets certain requirements. Table 1 summarizes these:
Goal | What it implies |
Make content reusable | Content is granular |
Enforce structure and consistency | Content is structured and semantically rich |
Reduce translation costs | Content is format-independent |
Personalize content and make it customer- or product configuration-dependent | Content is enriched with metadata |
Introduce a customer self-service solution | Content is precise, easily discoverable, and context-sensitive |
Assemble content automatically based on the product configuration | Content can be manipulated by machines |
Table 1: Content goals and requirements
As you can see, reaching the new goals requires your content to be transformed. This transformation requires certain efforts, which are listed in Table 2.
Effort | What needs to be defined |
Content restructuring |
|
Metadata modeling |
|
Information typing |
|
Content profiling |
|
Structures for dynamic content assembly |
|
Content delivery model |
|
Training the team |
|
Table 2: How does the content need to be transformed?
Is an all-out implementation required?
Looking at the list of possible efforts might feel scary and overwhelming. But the good news is that not all efforts have to be made from day one.
To help you assess the efforts required to achieve a certain goal and understand what efforts should be increased and when, take a look at Figure 1, which visually demonstrates the share of different efforts required for achieving different goals.
 |  |
 |  |
 |  |
Figure 1: Different goals require different efforts
For example, if your goal is to make your content reusable at least on the topic level, the content will likely need some basic restructuring to make it more granular. Additionally, to let content authors find the content that they can reuse, the content should be labeled with searchable metadata. However, extensive information typing is not necessarily required at this point.
Content personalization, however, will require stepping up the efforts for introducing information typing and building a solid metadata model. Perhaps some additional content restructuring will be needed too.
We will now review several real-life projects that I have managed in different roles. These will show you what needs to be considered and how efforts should be tailored towards the goals.
Case Study #1:
Propagating the value of structured content from the documentation team to end customers
Our first story is about a company that makes industrial printers. Although they had several product lines and highly configurable products, all customers received only generic documentation. But even that documentation was poorly written (in an unstructured format) and lacking standards. This resulted in both high content production costs and high service costs because customers could not find the information they needed and had to call customer service.
The ultimate goal was to reduce the costs of both content production and customer services. This was done in two stages:
Stage 1
The goal of Stage 1 was to reduce the costs of content production, translation, and maintenance. The main beneficiaries at this point were the content authors.
With a considerable amount of potentially reusable content, the documentation team had to find a way to update content quickly. Therefore, making content reusable and format-independent was a top priority, dictating the nature and scope of the efforts shown in Figure 2.
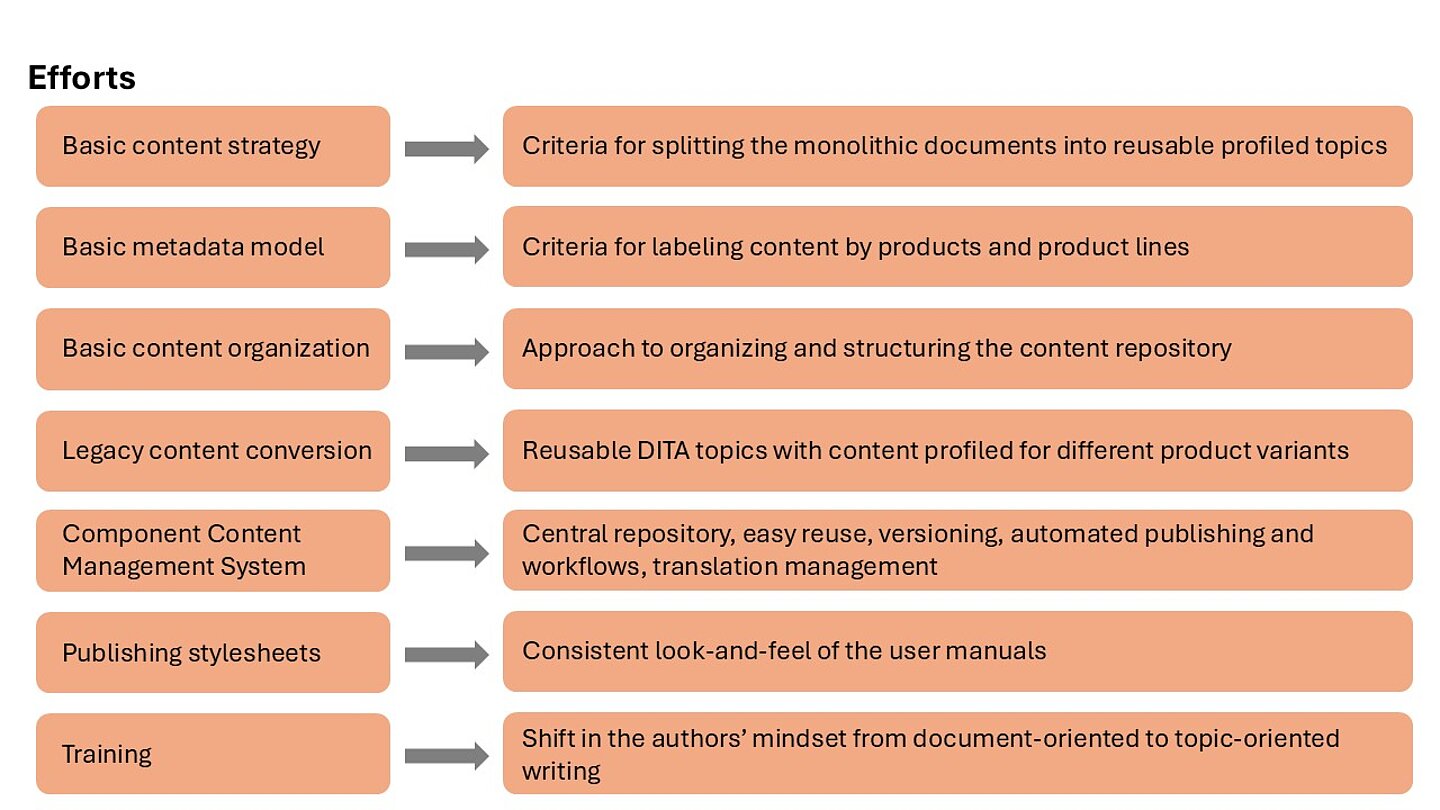
Figure 2: Efforts to reduce the costs of content production, translation, and maintenance
Therefore, the return on investment was an increase in the efficiency of content production and maintenance (see Figure 3).

Figure 3: Benefits of the efforts taken in Stage 1
Stage 2
By the end of Stage 1, the main beneficiary of the improved process was still the documentation team. There is nothing wrong with keeping the documentation team happy and efficient, but what about end customers?
Stage 2 was about increasing customer satisfaction. The metric used to measure this was the case deflection rate. In other words, customers should be able to find all the required information by themselves without having to call the service center.
At this stage, a content delivery platform was introduced to provide customers with access to granular, precise, and easy-to-find product information. However, as we already know, new wineskins are required for new wine. This was the time to step up the efforts to achieve the new goals shown in Figure 4.
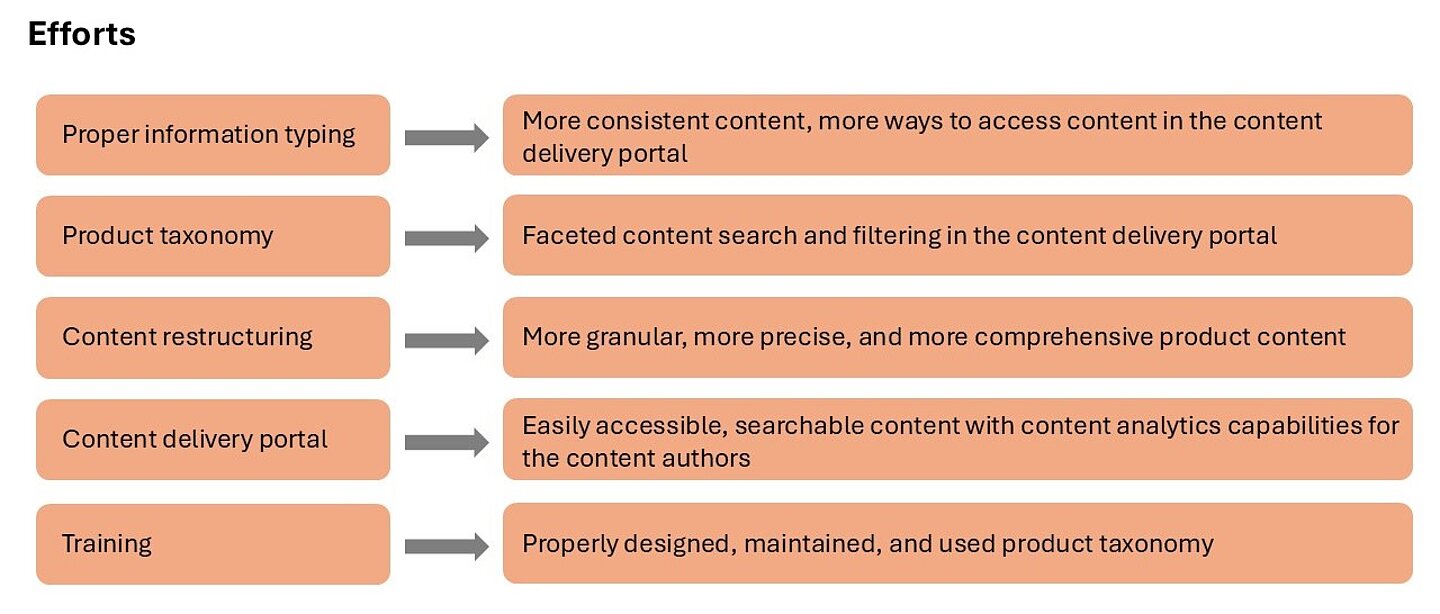
Figure 4: Efforts to increase customer satisfaction and improve deflection rate
This time, the return on investment focused on propagating the value of the structured content to the end customers (Figure 5).

Figure 5: Benefits of efforts taken in Stage 2
Case Study #2:
Automatically assembling product documentation based on product configuration
The second case study is of a European manufacturer of passenger airplanes. Aircraft are highly configurable products. When an aircraft manufacturer sells aircraft to airlines, each airline receives its own configuration of the aircraft. For example, an Airbus 320 sold to Lufthansa and KLM would have two very different configurations. Even within a fleet owned by the same airline, it is unlikely that there will be two airplanes with an identical configuration.
Since the configuration directly affects the way the aircraft is operated, the entire flight documentation had to be assembled dynamically for each airplane.
Thus, the goal was to ensure that the pilots had interactive access to the correctly assembled flight documentation of the specific aircraft they were flying.
The efforts were focused on redesigning content in a way that makes it machine-readable and ready for automated assembly and automating all processes related to content creation, reviewing, management, and release (see Figure 6).
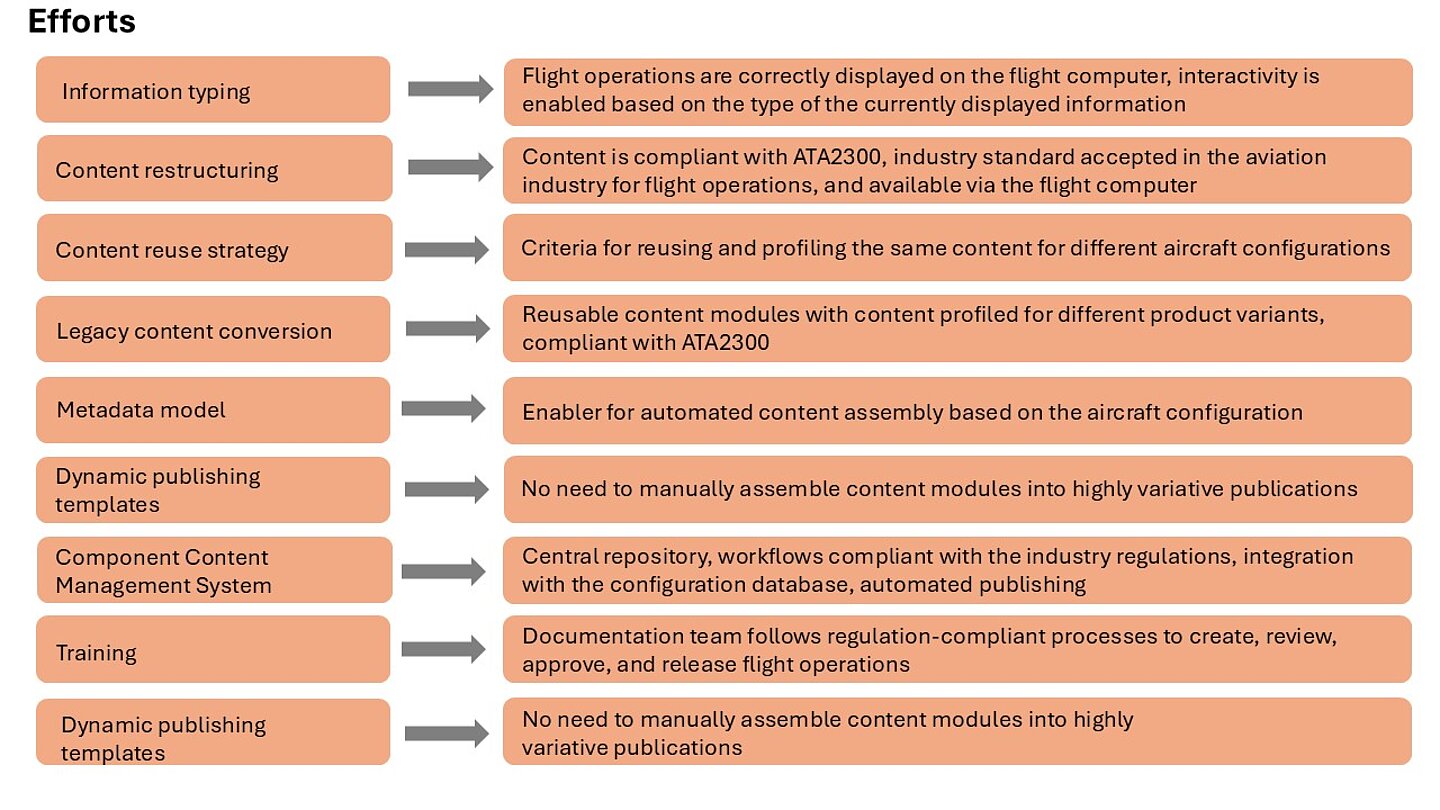
Figure 6: Efforts for redesigning content for dynamically assembled documentation
However, automated content assembly also means that you have to think about potential issues not considered earlier. One of them is how you handle cross-references between different parts of your documentation. When you write a monolithic book, you always know which pieces of content go together. You can safely add cross-references from one topic to another.
But when content is assembled automatically, there is no guarantee that the target topic is valid for a specific configuration. This means it may not become part of the operating manual of a specific aircraft and could potentially result in broken links.
In the aviation industry, cross-references are handled using the concept of containers. Imagine a topic providing a general description of an aircraft door. This description refers to another topic that describes the door’s locking mechanism. However, the door-locking mechanism is different for various configurations of the aircraft, so there are different topics explaining that mechanism. To which of these topics should the source refer?
The solution is to put all variants of the topic describing the locking mechanism into a container. The reference in the source topic points to the container rather than to a specific topic. When a publication is generated based on the aircraft’s configuration, filtering is applied to exclude the topics that are not applicable to this configuration. This way, the cross-reference is always resolved correctly.
The return on investment was to ensure that the mission-critical information was correct, complete, and available to the pilots (see Figure 7).

Figure 7: Benefits of efforts taken to redesign content
Case Study #3:
Ensuring automatically assembled content is correct
Another example of product documentation that needs to be tailored to a specific configuration is from the car industry. Getting a generic user manual that describes all the features and then states that this feature is unavailable in your market or for your configuration can be a frustrating and disappointing experience for customers.
Making content configuration-specific requires labeling portions of content in a way that indicates the validity of features for a certain variant or configuration and then applying a filtering mechanism that excludes all irrelevant content.
If variant content is labeled correctly, customers only get the information relevant to their particular car. However, there are a few ways things can go wrong:
- The variant content is mistakenly not labeled at all and thus appears along with generic content.
- The wrong label is assigned to the variant content, so the content does not appear where it should but instead appears in a configuration where it shouldn’t.
- A label is assigned at the wrong level of granularity, causing empty or even invalid content elements.
While the latter case might be relatively easy to identify (provided that the filtering mechanism notifies authors about invalid content), the first two cases may only be discovered when it is too late. For example, a critical safety warning might be accidentally excluded from the output, leading to disastrous legal consequences, or worse, endangering user safety.
Another source of customer frustration might be language. If you previously had generic documentation, some of the language probably needs to be adjusted. For example, it is common to see phrases such as “Depending on your configuration…”, “this function is not available in all countries”, or “if this function is available in your car…” in generic documentation.
Therefore, the efforts were focused on building the mechanisms that ensure only relevant content is delivered to users (see Figure 8).
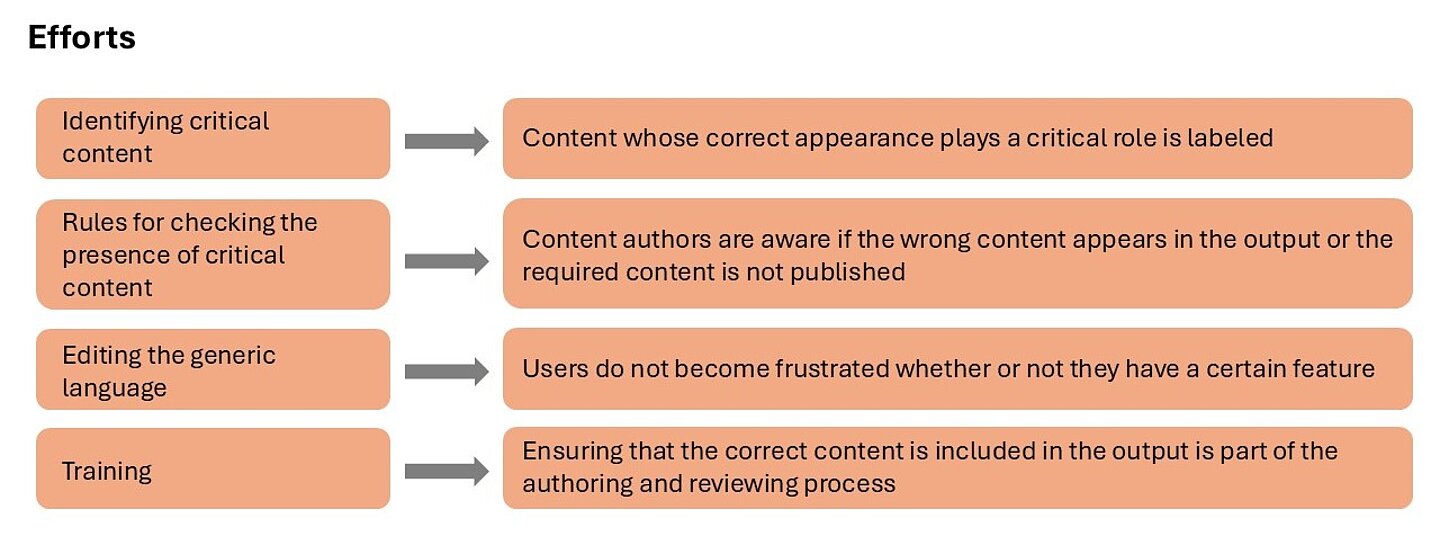
Figure 8: Efforts to filter out irrelevant content
The return on investment was the assurance that critical content was correctly included (Figure 9).

Figure 9: Benefits of efforts taken to make content configuration-specific
Conclusion
You cannot put new wine into old wineskins – but that does not mean that you have to start from scratch. Your goals dictate the nature and scope of your efforts. Some goals require rethinking your content strategy. Understanding how the goals are mapped to the efforts, which efforts are relevant in each case, and how the efforts can be managed is key to a successful implementation of your content management and content automation initiatives.