
With the rise of Artificial Intelligence, the requirements for technical documentation have changed. Different systems are now accessing content dynamically, making intelligent searches by using Natural Language Processing (NLP) or scripts to automatically extract specific information. Typical use cases include connecting chatbots to our content or extracting content for usage in customer tools.
But while working on adapting our customer information for machine-reading, we must not forget the human reader. We must create information that is as good as possible for both human and machine.
Scripts and integrations with external systems have added complexity and dependencies to our content. The chain from a technical writer creating content to the reader accessing this content has become longer and today includes more interfaces, increasing the spectrum of things that can go wrong.
In this article, we provide tips and tricks on how to prepare your current documentation for machine readability without losing your human reader. You will also learn of a use case where the improvements helped both humans and machines to find relevant content faster.
Images
It is hard for a machine to interpret images. Here at Ericsson, the most used template for installation instructions has the human brain in focus. Our instructions are illustration-driven and influenced by examples from companies like LEGO and IKEA. Each step in our manuals includes a detailed image and a short text. These instructions are easy to follow and work fine even for people who do not have English as their first language.
With the assistance of previous experiences, our human brains can draw conclusions and put an image into a given context. This, in general, does not apply to machines. Yet, even if you do not have a system with image interpretation, there are a few things you can do to improve machine readability:
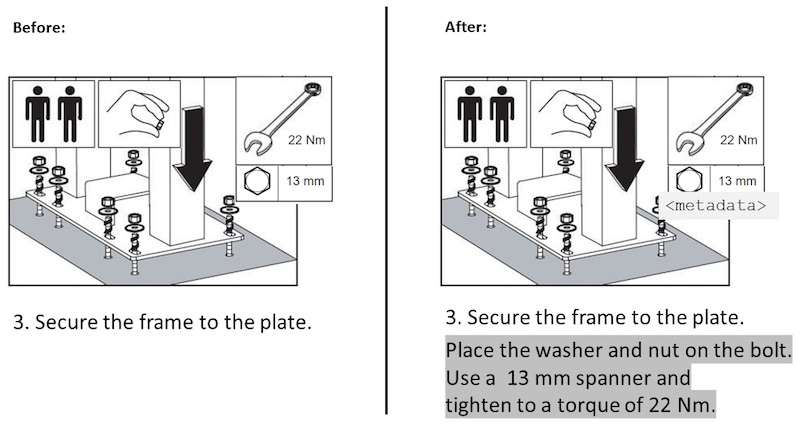
Figure 1: Increasing machine readability of content in images
The example in Figure 1 shows how to fasten a frame to a plate. As a human, we can draw many conclusions from this image. We can easily see what tools to use, in what order to place the nut and washers, and how firmly the nut should be tightened. The text simply summarizes the task by instructing you to “secure the frame to the plate.”
All information with regard to tools and parts is included in the image. This means that a text processing system cannot draw conclusions from the information in the image. An additional descriptive text can improve this by providing important keywords.
You can, of course, also add metadata to the image, but such text is typically not visible for the human reader. Make sure that information is applicable in both image and text and understandable by both humans and machines. Ask yourself what the image is showing and what information a machine can extract.
Relations within the content
The relationship between information elements is another example of machines having a hard time grasping the writer’s intent. While it is easy for the human brain to determine how elements are connected, a machine requires these relationships to be clearly defined.
Figure 2 shows an image and a table. As long as the image and the table are published in the same context, it is easy to understand that they relate to each other. The human brain understands the connection between the letters in the figure and the letters in the table. However, the machine might require additional information.
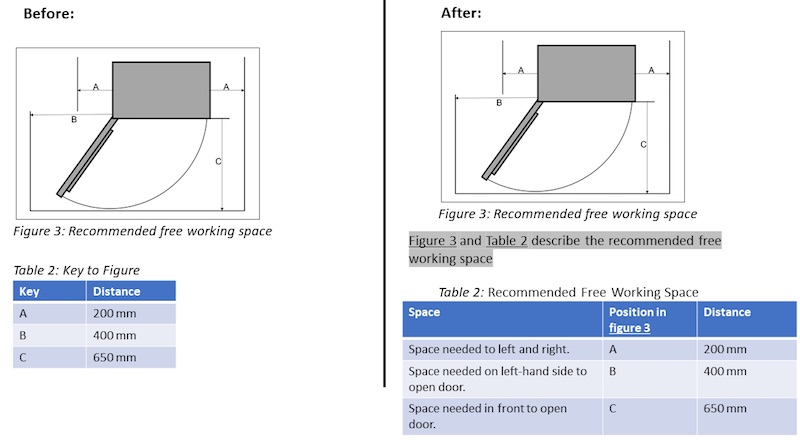
Figure 2: Increasing machine readability between two information elements
One way to state the relationship between the two information elements is to add a descriptive text, for example: “Figure 3 and Table 2 describe the needed working space around Product X”. The added column named “Position in Figure 3” helps us to refer the letters in the figure to the letters in the table.
When working with content in a content management system (CMS) you cannot be sure how the elements will be shown in the publishing environment. Machine processing of information elements might change the order of your information elements. You can solve this issue by providing unmistakable links when referring to information elements.
Table design
Information in table format is generally easy to understand for both human and machine. But there are a few things to think about:
- Before designing the table, ensure that you know what kind of questions the information in your table will answer and what values are given.
- Store one value per cell and avoid merging cells. It is tempting to merge cells with the same value in more than one row, but it will make it harder for machine-reading.
- Create one table for each subject. It is better to create more than one table than trying to fit a lot of information into the same table.
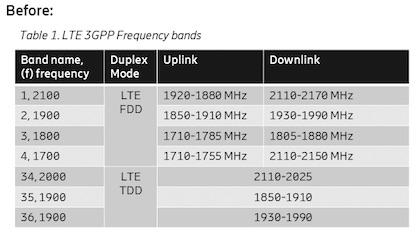
Figure 3: Frequency bands of different types in the same table
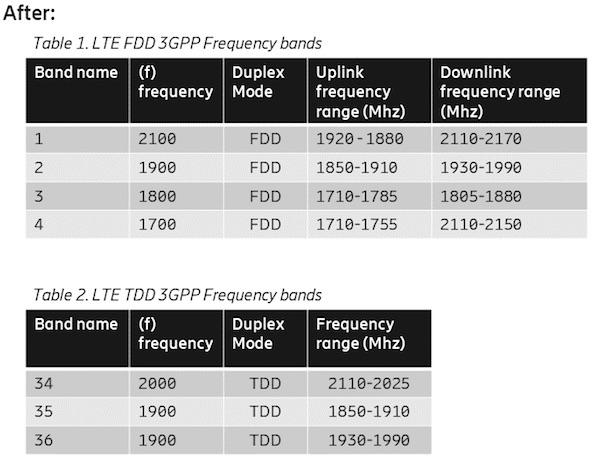
Figure 4: Tables split in two, one for each band type
Titles, headings, and captions
Descriptive titles, headings, and captions are essential when writing machine-readable text. The title must describe the information element. The heading can instruct both the human reader and the machine on what to expect from that topic or information element.
The DITA standard also advocates precise topic titles. Following these principles will also increase machine readability. A title must be self-supporting even outside the published context. A good topic title or heading will help both the human reader and the machine to know what the topic is about and what kind of topic it is.
As an example, a topic with the title “Overview” does not give enough information to be published standing alone. Simply adding the product name can already improve it: “Overview of Product X” or “Overview of the Installation Procedure for Product X”.
Organizational-specific guidelines and rules on how to structure titles and captions will help both humans and machines to navigate them. Such guidelines will also help content creators to write concise and consistent titles, thus improving semantic understanding.
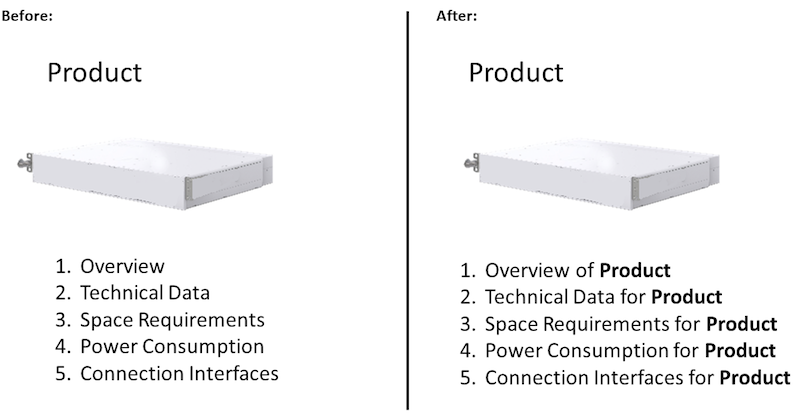
Figure 5: Improving the machine readability by including the product name in each topic title
Case study: Fifteen minutes to solve an alarm
Let us give you a real-life example showcasing how the restructuring of the documentation can make it easier to find information, reduce the amount of text, and increase machine readability.
All over the world, Telecom operators have network operation centers where people monitor Telecom networks and secure that they are up and running. Every now and then, faults occur in the networks, and alarms are sent to the people at these network operation centers.
When the staff in the network operation centers receive new alarms on their monitors, they often only have 15 minutes to acknowledge and identify the alarm and to make first attempts to solve the problem. At this stage, the priority is on fixing the problem with analytics and preventive actions to be followed up later on.
The staff at this particular network operating center informed us that it took them too long to find specific alarm instructions, and sometimes they could not locate them at all. And even once the necessary instructions were found, it could take too long to identify the particular information relevant to fixing the problem and resolving the alarm. Therefore, they often tried to solve the issues in other ways instead of following the step-by-step alarm instructions.
The Alarm Viewer tool
The staff at the Network Operations Center can monitor alarms in different ways, using different tools or log files. Yet, no matter which tool they use, the data relevant to understanding the alarm and for finding the correct instructions on how to solve the issue remains the same. That data is:
- Specific problem (the alarm name)
- Managed object (from where in the software the alarm is sent)
- Additional text (descriptive text about the alarm)
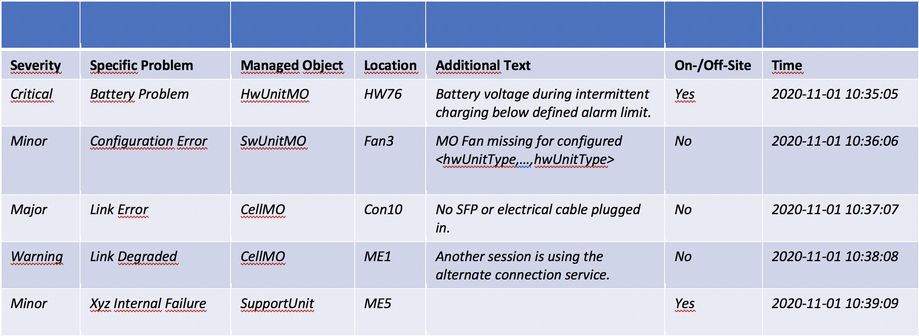
Figure 6: Alarm Viewer tool
It is the combination of these three elements – specific problem, managed object, and additional text – that determines which alarm instructions are needed. However, this information was often difficult to find in the old documents.
Alarm instructions structure: before and after
Before we restructured the alarm instructions, it was difficult to find the information needed to decide what step-by-step instructions to select.
It was difficult to find information on additional text and other information needed for solving the alarm. Instead, the table at the beginning of the alarm instructions document provided a lot of descriptive information regarding the alarm. Often, you had to scroll back and forth before you found the relevant step-by-step instructions. Hence, a great part of the response time was spent on finding information instead of solving the alarm. What could we do to make it easier to find the correct alarm instructions?
After the restructuring, the table at the beginning of the alarm instructions document is still there but, instead of describing the alarm, that table now has all the information needed to select the relevant step-by-step instructions. This information is provided in the Alarm Viewer. You no longer have to scroll back and forth. We moved all descriptive information on the alarm from the table to the specific topic in which you find the step-by-step instructions. This means that only the person interested in a certain alarm variant is guided to the descriptive information. This simple change allowed us to reduce the number of words in the table at the start of the instructions by 80–98 percent.
Machine-readable alarm instructions
Once we had made it easier for the human reader to find information in the alarm instructions, we decided to include them in the Alarm Viewer Tool to make it easier for the user of the tool to access the information. The links in the table at the beginning of the alarm instructions are now included in the Alarm Viewer Tool. This provides direct access to the topic that contains all information on the specific alarm variant.
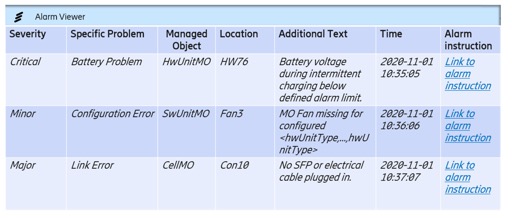
Figure 7: Alarm Viewer Tool with Links
Including the alarm instructions in the Alarm Viewer Tool allows much quicker access to the specific alarm instructions. With the restructuring, we made it easier for both the human and the machine reader to find the correct step-by-step instructions within the alarm instructions.
Machine reading – no freedom to change?
However, after we had restructured the alarm instructions and started to include them in the tool, we experienced some problems with this new function. We tested and retested the entire workflow to make sure everything worked. That’s when we realized that our alarm instructions matched the document instructions 99 percent of the time. However, the missing one percent was enough to cause machine reading problems. The mismatches were a result of changes to the storage areas that we had not been aware of as well as connectivity problems, all difficult to prevent.
We had been aware that there would be new users of our information and had identified and described the new interfaces and dependencies. However, we soon realized that our description of the interfaces and dependencies was not good enough. We had to make sure that the interfaces were better defined, dependencies better communicated, and responsibilities decided.
When you start to use machine reading, it can feel like you suddenly have more errors in your documents and that it is impossible to change the structure of your information or that it has become a lot more complicated. There is still room for changes, but it is a lot more restricted.

Figure 8: Machine reading challenges
Summary
The future will provide us with more intelligent ways to implement machine reading with the help of AI, machine learning, better scripts, etc. At Ericsson, we plan to continue to improve our customer documentation with the help of these new techniques to offer the best solution for both the human and the machine reader.