
Large Language Models (LLMs), Generative AI, and more specifically ChatGPT are the new kids on the block. They are shaking up not only the tech community but every stakeholder in every business. It seems everyone is trying to imagine how AI could impact, help, or transform their personal workflows and the operations of their organization. And the fear of missing out is reaching a crescendo. Leaders now wonder whether they’ll be overtaken by their competitors in integrating AI functionalities. Is this the metaphorical meteor that will wipe out slow-to-evolve dinosaur organizations? While time will tell, it’s increasingly likely that, as Andy Grove warned, “only the paranoid survive.”
Yet, for all the opportunities that AI might deliver, there are plenty that have already arrived. Take the classic authoring-to-consumption workflow:
- Create: Change the authoring process
- Validate: Monitor consistency of information across versions, time, and sources
- Translate: Go global at a lower cost
- Publish: Help users train themselves
- Search: Reinvent the search experience
- Read: Augment support agents
Below, we will map major changes that AI already enables.
Change the authoring process
There is a debate about whether GenAI could be used for writing technical documentation. But how can GenAI possibly know the details of a newly invented product? After all, technical information needs to be truthful, and we can’t risk AI “hallucinations”.
At Fluid Topics, we have always supported the notion that everyone inside a company, not just tech writers and a few domain experts, can contribute to knowledge creation. Being able to ingest any type of content, including unstructured documents such as Word files, Fluid Topics enables such creation by empowering each contributor to work with their preferred tool. Building a unified knowledge repository does not mean forcing a single authoring tool onto all contributors. However, the transition to this new paradigm requires tech writers to change their working methods and become editors and copywriters rather than interviewers and authors. This is where AI comes in.
Now, SMEs can write in their own capacity without having to worry too much about grammar, spelling, and style, and without creating too much additional workload for tech writers thanks to the use of GenAI for rephrasing content and enforcing general or corporate standards. The result? Drastic changes in SMEs’ and tech writers’ work processes:
- SMEs can write faster, use GenAI to rephrase content on the spot, and check the accuracy and truthfulness of what GenAI suggests. The process of writing-improving-checking becomes dynamic and real-time at the SME level, and tech writers are not involved until the SME is done.
- Only then does the tech writer review the content, now focusing on value-adding tasks such as aligning and connecting this new content into a larger content story.
One question about this new paradigm is: How does this complement or replace content quality checking tools (such as Schematron, Acrolinx, or Congree)?There is certainly an overlap, but currently, they are mostly complementary. Quality checks and corporate rule enforcement take place after GenAI in the process, though this may change in the future. Indeed, there is a chance that these vendors will integrate GenAI into their products to provide a full-featured tool supporting the SME-Author paradigm.
Monitor consistency
One of the major challenges in knowledge management and technical documentation is maintaining accuracy and consistency over time and across sources, essentially avoiding contradictory information.
It’s a familiar story: A manual explains procedures for version 1 of a product, another guide describes how to troubleshoot the product, and a support agent has written an article with a few tips about it. After a few years and various product iterations, the now-bestselling product has gone through two major evolutions, has four variants, and has been adapted to three different export markets. The related documentation should have evolved too, but did it? How about all the translated content? And the copy-and-pastes made a few years ago to produce a quick start guide? And all the knowledge base articles in the help desk tool?
This is a challenge every company faces, affecting productivity, if not trust, in technical content as well as raising its own security flags. Single sourcing – one tool to write them all – pretends to address this issue, but we now know that it is rarely applicable at scale. Each stakeholder uses their own authoring tool of choice (you can’t force product marketing to write in DITA, right?), not to mention the copy-and-pastes into Word files, articles, and emails.
This is where AI comes to the rescue. AI can be used to read all versions of your documentation, and all bits of information that your teams have created, and detect incoherence and inconsistencies. It can reveal what piece of content should be updated and act as a real-time check on production: When writing something or using a piece of content, the system can automatically check it for consistency with existing material.
The capacity of AI to help maintain a sound, consistent, and reliable corpus of information is tremendous, and this further fosters the opportunity to allow every stakeholder to become a contributor.
Go global at a lower cost
An important decision that companies that sell worldwide need to make is how much of their content to translate into how many languages. Translation represents a cost both in terms of money and time, and the availability of translated content can delay the release of the documentation, if not the product itself.
The progress of machine translation (MT) in the past ten years has helped reduce both financial costs and the time required to generate a translation. Indeed, MT has become so good that one can now ask if it is possible to rely on MT alone and remove humans from the translation process altogether.
The response is a hearty “yes” for three reasons:
- Technical documentation is written to be unambiguous and easy to grasp from a language perspective. No long and convoluted phrases, no double negatives, irony, or understatement. In most cases, straightforward to read means straightforward to translate.
- The vocabulary itself is limited. Even though it can be jargon-heavy, these terms are known. Glossaries and translation memories contain all the necessary details to support the specialization of an MT engine.
- If you previously translated “manually”, with experts reviewing and fixing, then you have a history of validated translations, which is exactly what is needed for training modern MT engines and earning even better results.
Recent experiments have shown that MT translation has become good enough for businesses to fully rely on it without the need for human validation. Note that current DNN (Deep Neural Network) engines are still a bit better than LLM-based translation, but the combination of both may yield even greater accuracy in the future.
What does it mean for you? In short, you can drastically simplify your publishing workflow.
Imagine that, once your content is written in its original language, it can be published as-is to your content delivery platform, and that it is immediately available in as many languages as you desire: 10, 20, even 40 or more. Whatever the number, the trick is to translate content on the fly, making it look like your content exists in, say, 23 languages, even if it is only drafted in one. The search queries of the users, the search results pages, the displayed content – everything must be translated in real time.
You might also choose to balance your strategy between pre-translated content (MT-based with or without validation) and live translation. You could, for example, author in English, pre-translate and validate in Japanese and Chinese, pre-translate without validation in Spanish and French, and offer access to your content in 18 more languages, for which you have far fewer customers, with real-time translation. The possibilities are endless: Only customers and partners could have access to on-the-fly translation; you could leverage feedback from readers to spot translation issues; you could limit pre-translation or validation to the most-read content. Content usage analytics certainly are of great help here and would assist you in making the best decision.

Figure 1: On-the-fly Machine Translation offers a flexible, cost-effective option to traditional pre-translation.
Help users train themselves
Technical documentation is extensive as it must be both accurate and comprehensive. But sometimes this comes at the cost of readability, preventing users from being able to rapidly search and find the information they need.
Imagine a technician trying to understand a maintenance task, but the procedure is spread across 40 pages, described in every possible detail. One way to simplify the reading is known as progressive disclosure. It’s about hiding or showing part of the content dynamically by using folding-expanding blocks. But this approach puts a burden on tech writers as they must add semantic markups to the content so that the UI knows which content should be displayed or hidden and when. What’s more, the writing must be done in a way that any combination of displayed and hidden content still makes sense to the reader. That’s without mentioning that this way of revealing content does not apply to all situations (for example, if the information the user wants is scattered across multiple chapters or documents).
This is where LLMs come to the rescue. They are good at summarizing, which means you can feed them dynamically with content that is not even specifically prepared for the purpose and request a ten-line, one-page, or three-page summary.
Consider a new kind of experience offered to a user who wants to learn about a feature or function of your product. The user could start by asking a simple question: “How can I fix this problem?”, or “What procedure is needed?”
The delivery platform that holds your documentation can display the supporting content, but instead of suggesting links to pages and forcing the user to deep dive straight into that content, an overview is provided. The reader can then bookmark the content for later use, reviewing the details as needed.
The possible scenarios are endless. Information discovery and self-training is certainly an area where GenAI is helpful, as it can automatically derive shorter or different representations from the extensive foundational documentation. This not only solves the problem of having to create specific content to train newbies – a costly task in itself – but also of having to resync the training material with the tech doc as products evolve.
Reinvent the search experience
Search engines have made a quantum leap in the past ten years with the advent of language models and probabilistic evaluation. They have become more relevant and allow for dynamic personalization of results. Hence, modern search technology, such as that which is integrated in Fluid Topics, significantly outperforms TF-IDF-based engines such as SolR or Elastic. Companies that are still relying on this outdated technology and struggling to provide a premium search experience to their users should consider switching!
LLMs are pushing language models to new heights, enabling an evolutionary step in the search experience. Being trained on large content sets (billions of pages), LLMs are good at dealing with natural language and concept searches, a big difference in comparison to keyword searches. But their limitation is that they are generic models, i.e., they are not trained specifically on your content. They know little about your products or about as much as they know about those of your competitors. As a result, used as-is, they are not able to give accurate and specific replies concerning your products. Moreover, recent tests and studies have shown that fine-tuning an LLM (even a small one) with your content does not necessarily yield better results.
But there is a path forward. By properly articulating modern search technology and GenAI (i.e. small and large language models), you can get the best of both worlds and build new ways to query and interact. Multiple use cases are possible. The most obvious include:
- Search result consolidation: A user runs a search and multiple documents are listed, sometimes from multiple sources (ref guides, troubleshooting procedures, etc.), all of which are relevant. Opening and reading each of them can be a cumbersome task, but leveraging GenAI to generate a single consolidated reply can deliver a superior UX.
- Question-answering: Instead of returning lists of documents through keyword search and letting the user read the doc to find a precise answer to a question, AI can generate direct replies to questions.
- Dialog and assistance: A user can start with a question to which the AI replies with a set of content, a summary of that content, or a precise answer. Then the user further queries the system to get to the next step. Imagine this user talking to an expert who knows all your content by heart, delivering information piece by piece through a dialog as the user progresses through her problem-solving journey.
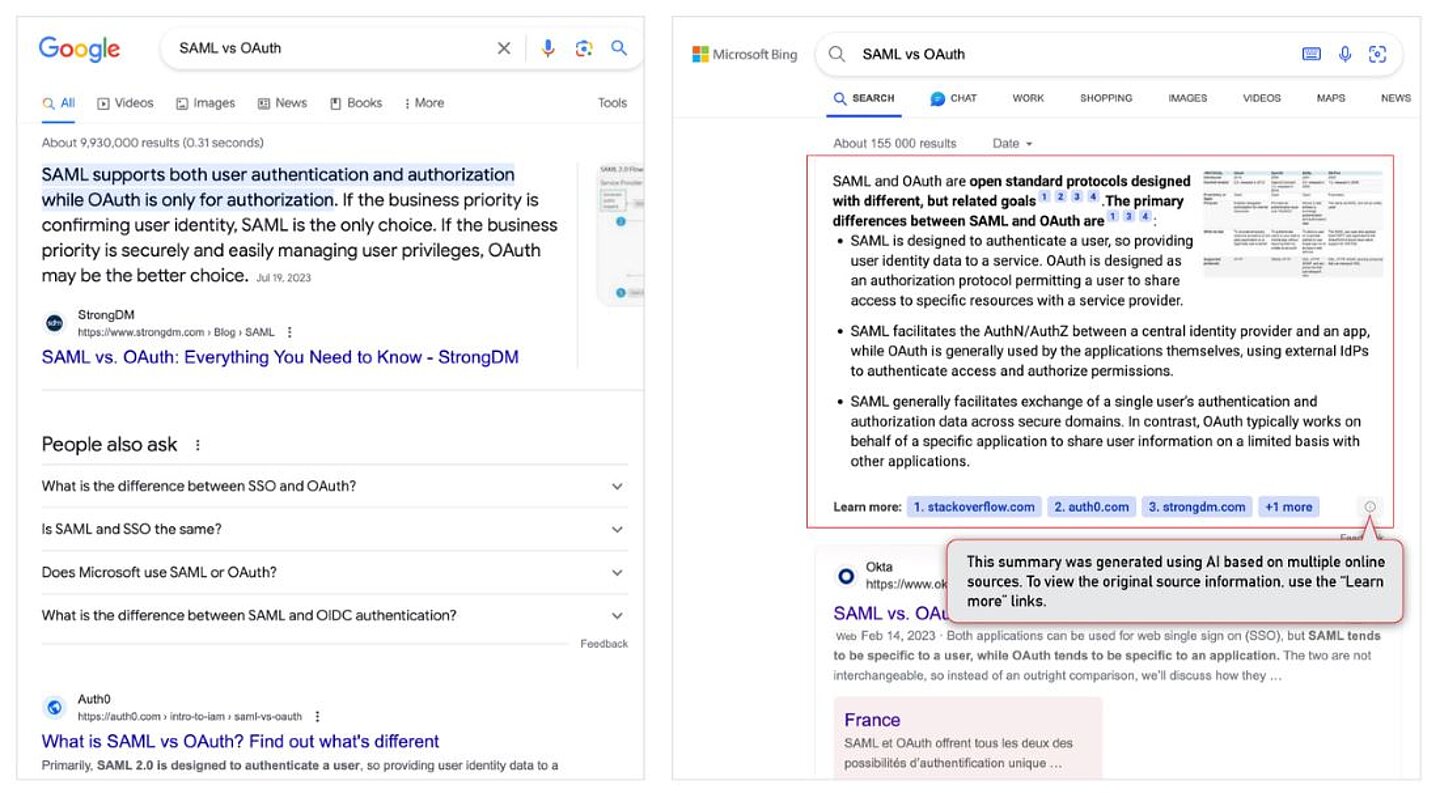
Figure 2: Bing (on the right) offers a new user experience by consolidating search results into replies.
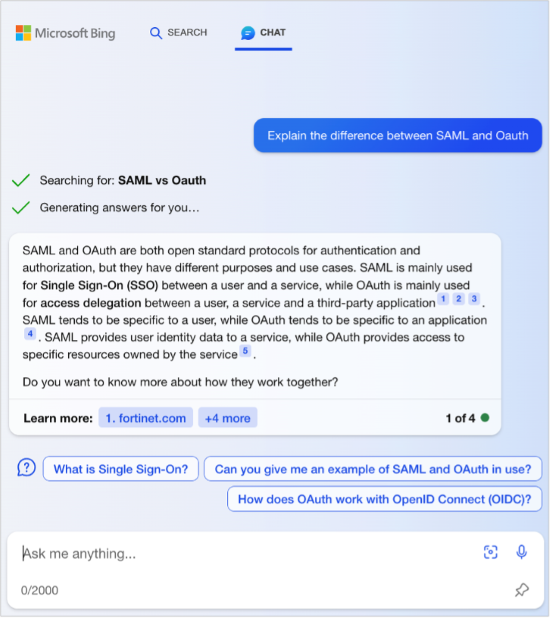
Figure 3: Step-by-step assistance with Bing Chat
Augment support agents
Replying to support cases submitted by customers is either boring or complex.
If boring, it’s because many of the questions raised by users are basic and recurring. Support agents tire of repetitive work. They overcome this scenario by creating a dedicated knowledge base, a set of predefined answers they can copy, paste, and adapt if necessary.
If complex, it’s because the remaining questions are unusual and advanced. These queries require the agent to search, read, search again, ask for expertise, and derive a proper answer from all this documentation harvested from multiple sources. It’s like solving a puzzle by assembling pieces of information to then craft a nice, clear picture. The less experience agents have, the more time and help they will require from other agents and experts.
All this costs a company time and money. Slow replies create user discontent. So, what if you could automate part of the process and reduce the time to reply to both boring and complex cases by a third or even half? This is what GenAI enables.
By leveraging a combination of search technology and generative AI, you can write replies to cases. It works as if you had an expert familiar with all your documentation and able to respond to any question in just a few seconds. But you cannot take the risk of providing a wrong answer and, of course, GenAI is not perfect (but neither are humans). So, the approach recommended here is to use this Search+GenAI combo to prepare a reply and have the support agent check, validate, and fine-tune the reply. What would have taken five minutes now takes two. What would have taken one hour now takes 20 minutes. Not only that, it helps junior agents to be up and running right away. They can check the supporting documentation identified by the bot and included for reference in the reply, as well as the generated reply, and hence learn incrementally as they review and validate replies. The benefits are numerous, whether increased speed, accuracy in writing, or quicker onboarding of new hires.
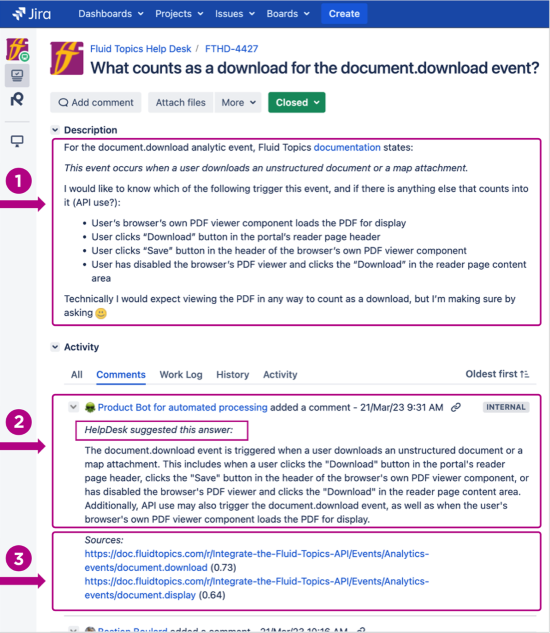
Figure 4: Suggesting documented answers with GenAI can drastically improve the efficiency of support agents
Conclusion
These are just a few scenarios in which GenAI can be applied to tech doc to transform a business. We can think of many others, such as:
- Delivering a better content reading experience: Explain code examples or translate a code example from one programming language to another on demand.
- Smart glossaries: Explain a term in context, reformulate content to aid comprehension, etc.
- Assistance in replying to RFI/RFP questionnaires: Ask your presales engineer how much they love filling in these spreadsheets that are always the same, but not so much so that you can copy-paste or reuse blindly. What if this could be automated?
- Deriving sales/marketing pitches and technical stories from tech doc: Suggest five bullets about this product, suggest a short description, etc.
The opportunities are limitless, and they all testify to a quantum leap in how information can be created, managed, and leveraged to transform the customer experience. Software platforms are evolving to integrate and deliver this transformation, and it’s going to be an exhilarating journey.
Are you ready?
Want to learn more? Meet our author Fabrice Lacroix at tcworld conference 2023 as he will present a live demo of GenAI applications. "Six applications of GenAI that have proven to transform the value of Tech Doc" When: November 14, 2023, 4.30-5.15 PM Where: Plenum 1 |
The end of formal knowledge modeling Knowledge modeling, also called Semantic AI, is the willingness to describe everything we know about a subject in a formal logical model to which reasoning can be applied. This quest began with the history of modern computing. After the failure of expert systems in the 80s (a very programmatic approach based on decision trees and inferences on predicate rules), the discipline was revived in 2005 with the idea of the Semantic Web devised by Tim Berners-Lee, the inventor of the Web. It led to the emergence of ontologies and knowledge graphs, a set of concepts, properties, and relationships in between describing a domain. Even though intellectually interesting, modeling a domain (i.e., designing an ontology) is a lengthy, highly technical endeavor, and once designed, ontologies are still difficult to instantiate (populate the graph) and even more to maintain. Hence, ontologies and enterprise knowledge graphs never gained full traction. But one must keep in mind the objective. Why do we need ontologies? To describe a domain to eventually solve problems and reply to questions. How can I do this? How can I fix that? And ChatGPT has proven to be very good at it, at least as good in just a few months or years of development as semantic AI after decades of hard work. So, do we still need ontologies? One could argue that an ontology is, in fact, embedded in the billions of parameters of the LLM. These parameters can indeed be seen as dimensions of a vector space, not explainable, but large enough to model not only the language used to train the model but also the underlying knowledge contained in the text. Others will argue that semantic AI is even more necessary to bring control and explainability to GenAI, and that GenAI will assist in building and maintaining knowledge graphs at scale more easily. How to best articulate semantic and generative AI is an open subject to be reassessed as it progresses. |