
Today’s AI debate revolves around headline-grabbing issues such as misinformation, deep fakes, privacy violations, lack of transparency, social inequality, unemployment, and even the very fate of humanity. Yet, there are many substantive issues that concern all private and public organizations staffed with people like you and me. Poor use of GenAI can lead to brand damage, legal liability for libel or defamation, violations of privacy and intellectual property rights, copyright infringement, and bias and discrimination in social and business interactions. Quite frankly, such issues should concern anyone with a conscience.
Do good and do no harm
To protect employees, customers or citizens, as well as the environment, many public and commercial entities have adopted frameworks for corporate social responsibility (CSR); environmental, social, and corporate governance (ESG); and diversity, equity, and inclusion (DEI). Simply stated, these charters describe what’s right and wrong – that is, they define the moral principles that govern behavior and activities. They document what entities ought to do in terms of rights, obligations, fairness, society, and impact on humans and the environment.
Then in swoop ChatGPT and its generative brethren that can answer questions, write essays, explain complex theories, draw pictures – all based on easily stated requests. Its adoption was so viral that most CSR-ESG-DEI frameworks have not yet caught up on referencing Large Language Models (LLM) and generative pre-trained transformers (GPT). But given GenAI’s unfettered usage, organizations should consider bringing LLM and GPT under their CSR-ESG-DEI umbrellas. As with any technology, it will help ensure appropriate governance, use, and training of staff across linguistic, sociocultural, regulatory, and political environments.
Let’s examine two areas in which GenAI technologies run afoul of many such frameworks: its training data and the algorithms that create the magic of GenAI.
Please note that not all ethical concerns associated with GenAI in any potential use case could be addressed here. At CSA Research, we have focused our analysis of GenAI mostly on the deployment of the technology and the implications of its usage, especially in international or domestic multilingual venues. This is where the technology interacts with linguistic, sociocultural, political, and other locale-specific factors.
GenAI trains on many but limited sets of data
Most of today’s Large Language Models are trained on hundreds of trillions of parameters – derived from statistics found in large amounts of text – but they share two basic flaws: First, the data usually comes from web crawls, not from phone calls, meetings, or broadcasts (unless they’re transcriptions). This results in a training bias toward just one type of discourse. Second, and more troubling, most data input comes from a handful of economically significant languages. The disproportionate contribution of English risks further digital colonialism and undermines the hyperlocal potential by reducing large amounts of data to an anglophone statistical mean (Figure 1).
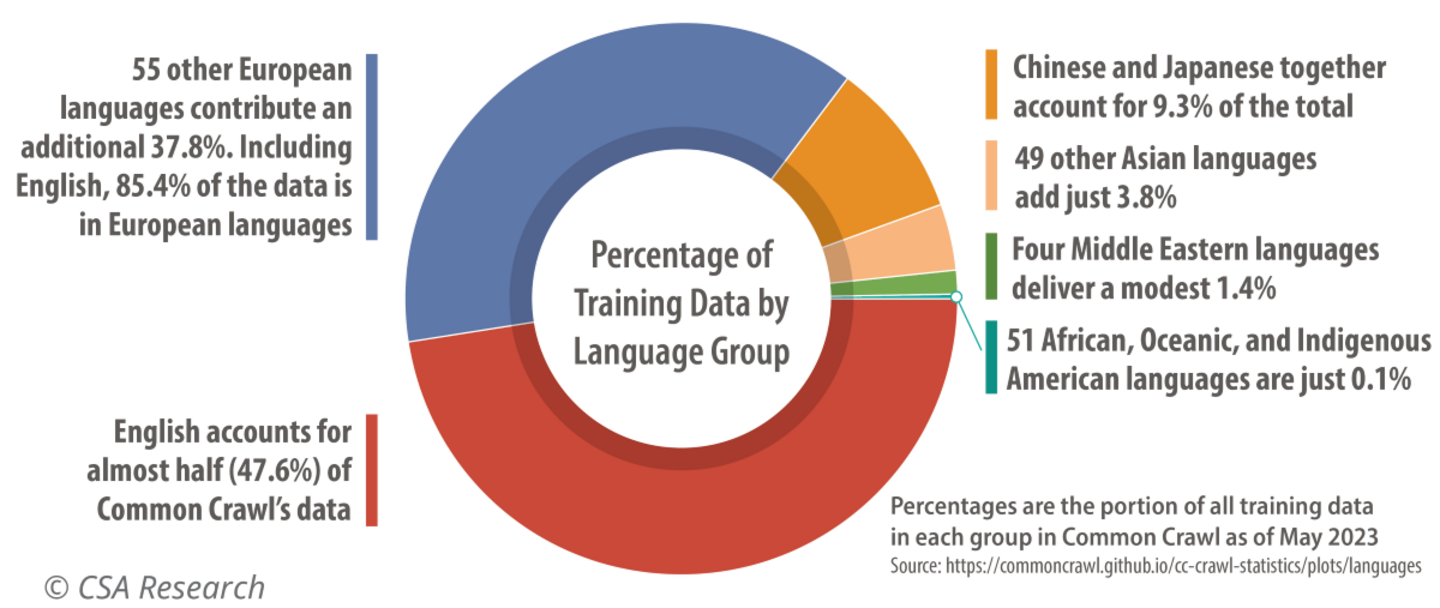
Figure 1: English and European languages dominate training data
Of course, the most popular LLMs have been released in just the last year or two. Some developers claim that they’re training their newest models on better, curated data. However, the most widely used still rely on Common Crawl data from nearly two years ago. A lot has happened since then, so you can expect – and observe – inaccuracies due to time lags, incomplete histories, and other problems due to the latency of training. There’s an enormous effort required to crawl, process, label, and otherwise turn terabytes of text and images into a usable model (Figure 2). This is why models aren’t more current.
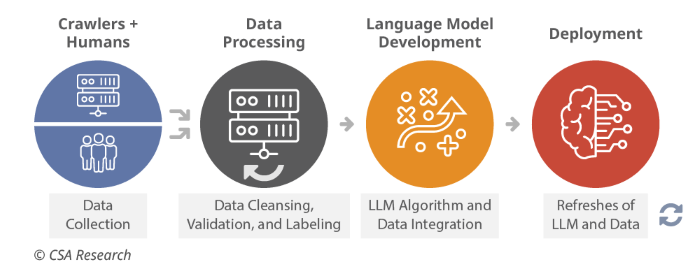
Figure 2: Humans’ and machines’ labor to build LLMs
Ethical concerns with GenAI usage
Now, let’s consider the GenAI data ecosystem from the perspective of enterprise practices you’ll find in CSR-ESG-DEI frameworks:
- AI requires a lot of data and energy. It takes unprecedented amounts of energy to compute the models and run the algorithms, a fact that some suppliers have acknowledged with statements about their carbon footprint. As it scales up to forecasted volumes, GenAI’s carbon footprint could rival that of cryptocurrencies, heretofore the biggest tech energy hog. In 2022, research cited in Stanford University’s Artificial Intelligence Index Report compared four energy-ravenous GPTs on their training runs (Figure 3). Keeping GenAI solutions operating and processing queries adds a lot of carbon dioxide to the atmosphere – adding users will ramp up the CO2 to ever more worrisomelevels.
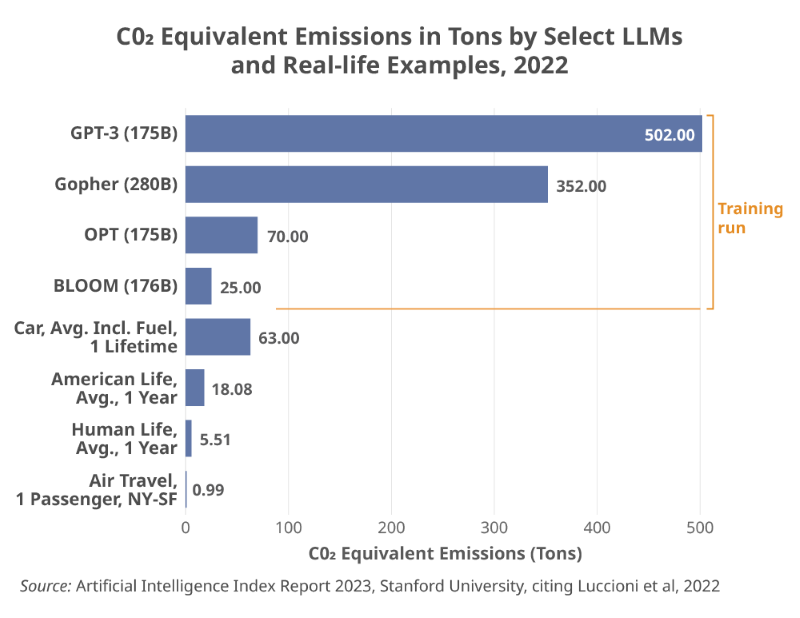
Figure 3: GenAI user costs roughly track energy usage and carbon emissions
- Data quality, accuracy, and currency suffer with the GenAI training model. Chief information and chief data officers require an ALCOA provenance (attributable, legible, contemporaneous, original, and accurate) for corporate data based on formal processes that ensure consistency of those characteristics over the data’s entire life cycle. Given their sourcing, the data associated with GenAI offer no such assurances. Trustworthiness and reliability – especially with multilingual and cross-border content – will not pass the usual smell tests applied to corporate data.
- Widespread access to GenAI tools will increase the amount of bad data. As if there weren’t already enough mis- and disinformed data out there, we can expect even more. A growing number of mass-market GPT users will rapidly create huge volumes of content in the form of answers to questions, summaries of topics queried, translations, and output pasted into other documents as-is. This GenAI-created content will pollute training sources as it finds its way into the digital commons, social media, and other categories of user-generated content (Figure 4).
Figure 4: AI-generated content will show up everywhere
Suppliers claim limited responsibility for GenAI
This is a rapidly changing technology market with potentially massive amounts of revenue and prestige at stake, so the situation can change overnight. Let’s consider what we’ve seen to date:
- Providers train LLMs on unbalanced data. We’ve already said this but can’t emphasize it enough: The training data is disproportionately biased toward American and European sources, usually as a matter of deliberate choice.
- GenAI data management procedures have yet to appear. The relative youth of the technology, velocity of change, and market competitiveness almost guarantee that long-established and trusted data management practices have yet to be applied. The cross-lingual nature of the sources exacerbates the absence of these processes and raises potential legal liability wherever GenAI tools are used.
- Low-cost labor enables generative AI. Mimicking the practices of many before them, developers outsource to low-wage labelers and other data miners in the Global South. Some have experienced PTSD from their labor labeling toxic content. What happens to these labor pools as GenAI matures and becomes self-sustaining? When organizations purchase products or services, their ethics frameworks should consider the environmental and human impact they have on the people and communities who create them.
By far the biggest issue is that developers of GenAI image-generators (such as DALL-E, Midjourney, and Stable Diffusion) and text-generators (like BlenderBot, ChatGPT, and ERNIE) maintain that their offerings are trial versions. This implies that they bear no responsibility for technical, ethical, or legal errors and omissions. Staff at some GenAI providers tried to stop their employers from launching GenAI-based chatbots but failed. Why? The revenue and prestige associated with this New Age technology eclipsed the caution that these companies previously had about AI.
Ethical use in multilingual operations
Based on the training data and generative AI algorithms, we have identified a host of core problems that raise ethical challenges for organizations developing or using GenAI, especially for cross-border or domestic multilingual applications. As these organizations modify their CSR-ESG-DEI frameworks, they should pay particular attention to flaws, demand solutions, and look to the broader market for alternatives.
Overcoming bias is the first challenge. The history of application development shows that algorithms learn from their human creators and retransmit bias – intentionally or by error, omission, or oversight (Figure 5). This results in ethnic, racial, gender, and other prejudices hardcoded into applications such as employment practices or loan approvals. GenAI could limit diversity, marginalize populations, and perpetuatedigital colonialism as output reflects sociocultural, political, economic, and other biases.
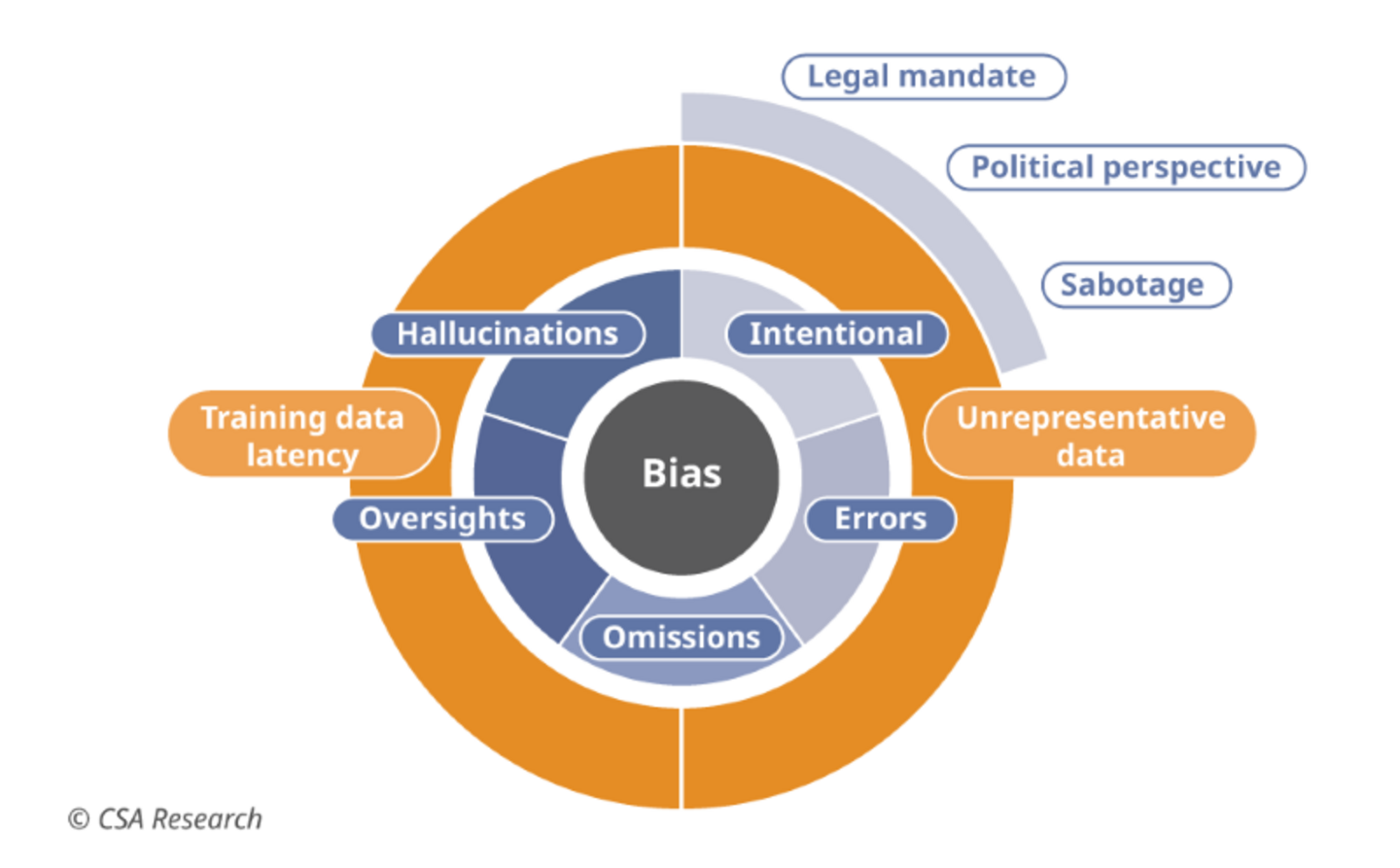
Figure 5: Algorithmic bias has many causes
Here are some steps you should take:
- Push your GenAI suppliers to take more responsibility. Insist on greater transparency. The disconnect between widespread usage, negative outcomes, and the “we are just field-testing it” perspective should grab the attention of every business, government, and LSP strategic planner and legal counsel. Expect colleagues responsible for information processing – data, content, knowledge, and human resources, among others – to scrutinize GenAI with enterprise criteria for data security, privacy, verifiability, integrity, and regulatory and legal compliance.
- Work with developers to make output explainable and auditable. While GenAI software producers may have in-house tools that can trace how their solutions work, they are unlikely to share them lest it expose the inner workings that account for a large part of their corporate valuations. This poses a fundamental ethical challenge to the trustworthiness of GenAI solutions.
- Replace the regulatory vacuum with active management. Developers face conflicting international and national laws that will mirror extensive and far-reaching directives like the EU’s existing General Data Protection Regulation or proposed AI Act. A caution: Many government regulators lack technical knowledge, so regulations could lead to total bans as they worry about everything from deep fakes to AI-generated porn to a repeat of ugly social media and toxic content that flourished with the Communications Decency Act of 1996 (Title V of the Telecommunications Act of 1996) to sci-fi machines going rogue à la HAL 9000 and TheMatrix.
- Increase access to lessen the digital divide. The Information Equity Initiativeadvocates that everyone has a right to high-quality digital resources, regardless of geography or income. Without this access, people will be marginalized economically, socially, and politically. Push suppliers to both increase the amount of non-English content in their training data and expand the sociocultural envelope of their sources to include more input from communities beyond the top few languages.
But the problems with GenAI aren’t limited to U.S.-centric solutions. Outside the anglosphere, expect to find Large Language Models developed for Chinese, Russian, and Farsi, not to mention other countries with pride in their languages and cultures – and their own political and moral bias (Figure 6). Without greater investment in finding, cleaning, and curating the training data, every model could reproduce the flaws in today’s LLMs – regardless of locale.

Figure 6: The advent of nationalist transformers – each with its own bias
Bring GenAI into your ethical framework
To be fair, none of the GenAI solutions on offer have breached any ethical boundaries that were not already under assault by existing software. Instead, broadly available GenAI applications have amplified long-standing ethical issues about Artificial Intelligence, leading some experts and governments to suggest banning the technology until it’s better understood.
Their concerns range across the entire life cycle, from the development and management of AI platforms to mass-market usage and CSR all the way to warnings about the end of humanity. Algorithmic and data issues raise a variety of ethical challenges around classic information technology imperatives: accuracy, security, explainability of results, obvious and hidden bias, privacy and informed consent, and ethical sourcing.
If you haven’t already done so, consider how GenAI philosophically aligns with your CSR-ESG-DEI initiatives to:
- Define the GenAI philosophy of the organization. This means applying AI output responsibly and legally wherever it operates, being inclusive across all strata of society across the planet, striving to eliminate inherent bias, seeking out unintentional bias, observing privacy rights, and closely monitoring compliance.
- Describe the role of GenAI. The code formally provides recommendations for deployment, management, monitoring, and handling of anomalies. It informs customers or constituents, partners, suppliers, and competitors of your policy.
Organizations can supplement their CSR-ESG-DEI strategies with the wisdom of others. For example, in 2021, UNESCO published “Recommendation on the Ethics of Artificial Intelligence,” its code of ethics for governments and companies. It presents values and principles for human-centered policies, and regulatory frameworks meant to ensure that GenAI technologies benefit humanity, not just investors. The UNESCO policy may seem overly “woke” to some people. However, that’s what ethical globalization is meant to do – avoid the flattening obliteration of a single language, economy, or culture.
Finally, any GenAI policy must comply with local laws and regulations. Your legal counsel and experts are responsible for every jurisdiction in which you operate, even if all you do is pass data through a country rather than operate there. Make sure that you factor data sovereignty and residency into any plans for Large Language Models and generative AI.

Figure 7: Foundation for a GenAI code of ethics
Conclusion
You can deploy GenAI responsibly, but doing so requires careful attention to the ethical and legal issues it raises. As you plan, look beyond the country of your headquarters and ask how GenAI will be used in – and affect – other locales around the world. Benefit from the good it does while limiting the bad things it can do.